ComfyUI工作流大全:15个模板直接下载
ComfyUI工作流大全:15个模板直接下载
为什么你需要现成的ComfyUI工作流?
ComfyUI凭借节点式可视化编排,成为2026年AI绘画领域最灵活的工具。但它的学习曲线也让很多人头疼——面对空白的画布,从零连线搭建一个工作流,光是搞清楚Checkpoint Loader、CLIP Text Encode、KSampler之间的连接逻辑就要花不少时间。
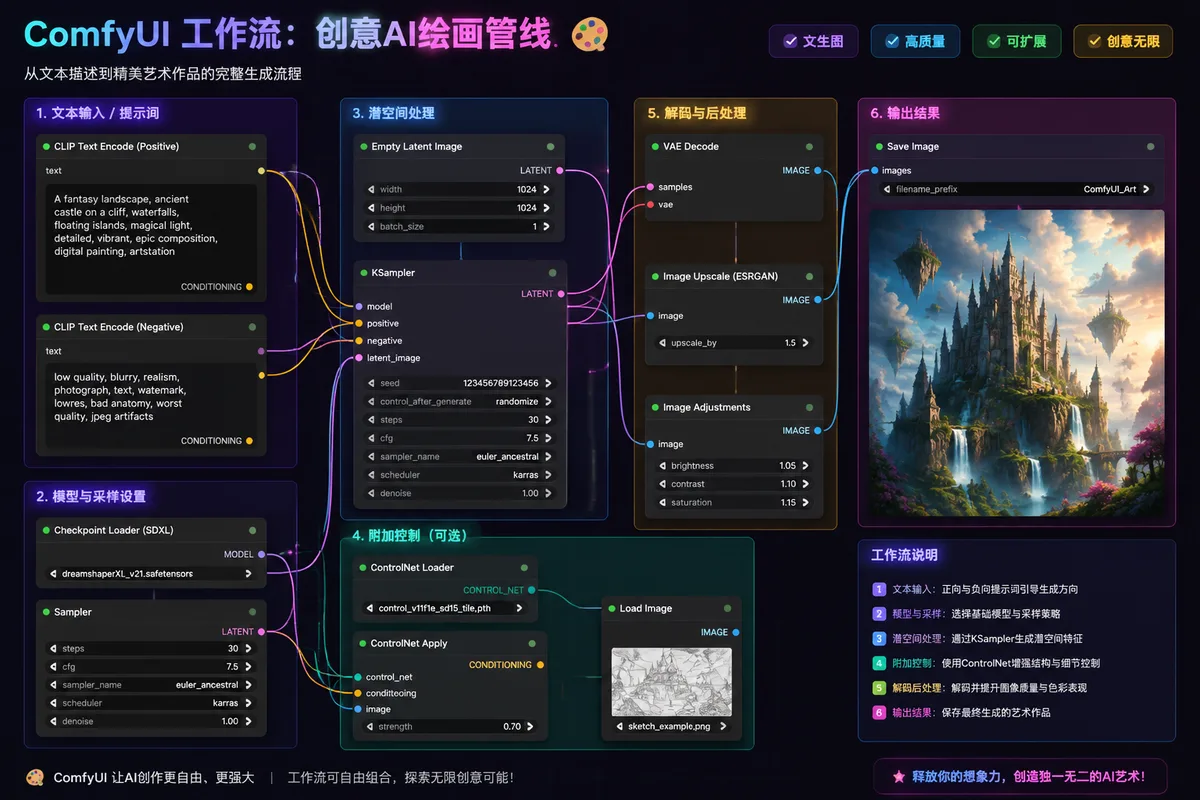
好消息是:ComfyUI的工作流可以导出为JSON文件直接分享。导入别人的工作流,等于拿到了一张”成品配方”——所有节点已经连好、参数已经调优,你只需要换上自己的模型和提示词就能出图。
本文整理了15个经过验证的实用ComfyUI工作流模板,覆盖从入门到进阶的常见场景。每个工作流都附带核心参数表格和使用说明,文末还有JSON文件获取方式。如果你刚开始接触ComfyUI,建议先阅读我们的ComfyUI入门教程。
一、基础生成类工作流
1. 最简文生图(Text-to-Image)
用途:入门首选,仅包含Checkpoint加载、提示词编码、KSampler采样、VAE解码和图像保存五个核心节点。适合快速出图测试模型效果。
适用场景:测试新下载的SD/SDXL模型,日常灵感快速出图。
| 参数 | 推荐值 |
|---|---|
| Checkpoint | SDXL/AutismMix/Anything V5 |
| 采样器 | DPM++ 2M Karras |
| 步数 | 20-30 |
| CFG | 7 |
| 分辨率 | 1024×1024(SDXL) / 512×512(SD1.5) |
2. SDXL 高分辨率直出
用途:在基础文生图流程上增加SDXL专属的Refiner节点,先由Base模型生成构图,再由Refiner精修细节。无需二次放大即可输出高质量大图。
适用场景:需要直接输出高质量1024+分辨率图片,如壁纸、海报素材。
| 参数 | 推荐值 |
|---|---|
| Base Model | SDXL Base 1.0 |
| Refiner Model | SDXL Refiner 1.0 |
| Refiner介入步数比 | 0.8 |
| 总步数 | 30-40 |
| 分辨率 | 1024×1024 / 1152×896 |
二、图生图与精准控制类
3. 基础图生图(Image-to-Image)
用途:加载一张参考图,通过VAE编码送入KSampler,用降噪强度(Denoise)控制与原图的相似度。值越低越接近原图,越高越自由发挥。

适用场景:风格迁移、照片转插画、同构图不同风格。
| 参数 | 推荐值 |
|---|---|
| Denoise | 0.5-0.75 |
| 采样器 | Euler A / DPM++ 2M |
| 步数 | 20-30 |
| CFG | 7-9 |
4. ControlNet Canny 边缘控制
用途:加载Canny预处理器提取参考图的边缘线稿,ControlNet引导生成过程严格遵循线稿结构。这是最常用的精准控图方式。
适用场景:保持构图不变换风格、线稿上色、建筑设计图渲染。
| 参数 | 推荐值 |
|---|---|
| Canny低阈值 | 100 |
| Canny高阈值 | 200 |
| ControlNet强度 | 0.8-1.0 |
| 起点/终点 | 0/1(全程控制) |
5. ControlNet OpenPose 姿态控制
用途:通过OpenPose提取人体骨骼关键点,生成的人物会严格遵循参考图的姿势。支持多人姿态检测。
适用场景:人物姿势复刻、动作设计稿渲染、电商模特换装。
| 参数 | 推荐值 |
|---|---|
| OpenPose预处理器 | DWPose(更精准) |
| ControlNet强度 | 0.9-1.0 |
| 检测对象 | 单人/多人自动 |
6. ControlNet Depth 深度控制
用途:用Depth预处理器生成深度图(远近关系),让AI理解画面的空间层次。相比Canny更适合保留立体感和光影关系。
适用场景:室内设计渲染、场景空间重构、电影级场景生成。
| 参数 | 推荐值 |
|---|---|
| Depth预处理器 | Zoe / Midas |
| ControlNet强度 | 0.8-1.0 |
| 起点/终点 | 0.2/0.8(后半段放手) |
7. IP-Adapter 风格/内容迁移
用途:不依赖提示词,直接用一张参考图驱动生成风格或内容。IP-Adapter比传统图生图更”聪明”——它理解图像的语义特征而非像素。
适用场景:保持人物一致性的系列图、风格迁移、品牌视觉统一。
| 参数 | 推荐值 |
|---|---|
| IP-Adapter权重 | 0.7-0.9 |
| 模型类型 | SD1.5 / SDXL 对应版本 |
| 注意力模式 | Style(风格)/ Content(内容) |
8. InstantID 人像保持
用途:上传一张人脸照片,后续生成的所有图片都保持同一张脸。结合IP-Adapter和ControlNet实现高精度人脸一致性。
适用场景:AI写真、证件照美化、同一人物的系列创作。
| 参数 | 推荐值 |
|---|---|
| 人脸检测 | InsightFace |
| InstantID权重 | 0.8-1.0 |
| IP-Adapter权重 | 0.5-0.7 |
| 去噪强度 | 0.4-0.6 |
三、放大修复类工作流
9. Hires Fix 高清放大修复
用途:先用低分辨率生成构图(快),再通过潜空间放大+二次采样修复细节。比直接高分辨率生成节省显存且构图更稳。

适用场景:SD1.5模型出高清大图、低配显卡友好方案。
| 参数 | 推荐值 |
|---|---|
| 初始分辨率 | 512×512 / 768×512 |
| 放大倍数 | 1.5×-2× |
| 放大步数 | 15-20 |
| 放大降噪 | 0.4-0.55 |
10. Ultimate SD Upscale 无损放大
用途:将生成图用ESRGAN/4x-UltraSharp等模型放大,通过分块采样避免显存爆炸。是目前效果最好的放大方案之一,带细节增强。
适用场景:将成品图放大到4K/8K用于打印、壁纸尺寸输出。
| 参数 | 推荐值 |
|---|---|
| 放大模型 | 4x-UltraSharp / 4x_NMKD-Siax |
| 分块大小 | 512-768(根据显存调整) |
| 分块重叠 | 64 |
| 放大步数 | 10-15 |
| 放大降噪 | 0.2-0.3 |
四、高级应用类工作流
11. AnimateDiff 视频生成
用途:在文生图流程上插入AnimateDiff运动模块,将静态扩散模型变成视频生成器。支持生成2-4秒的短视频片段。
适用场景:AI短视频创作、动态壁纸、社交媒体动图。
| 参数 | 推荐值 |
|---|---|
| 运动模块 | mm_sd15_v2 |
| 帧数 | 16-32帧 |
| 帧率 | 8 FPS |
| 上下文帧数 | 16 |
| 总步数 | 25-30 |
12. Inpainting 局部重绘
用途:用遮罩标记需要修改的区域,只在该区域内重新生成。配合VAE Encode (Inpaint)节点实现无缝融合。
适用场景:修手、换脸、去除多余物体、局部修改。
| 参数 | 推荐值 |
|---|---|
| 遮罩模糊 | 4-8像素 |
| 降噪强度 | 0.75-1.0 |
| 专用Inpaint模型 | 推荐使用 |
| 边缘填充 | 32像素 |
13. LoRA 多模型叠加
用途:同时加载多个LoRA模型(风格、角色、服饰等),通过权重滑块精细控制每个LoRA的影响力。
适用场景:角色+风格+场景的复合生成、微调画面特定元素。
| 参数 | 推荐值 |
|---|---|
| LoRA数量 | 1-5个 |
| 单个权重 | 0.3-0.8 |
| 触发词 | 必须包含 |
| 模型强度 | 叠加不超过1.0 |
14. 批量生图(Batch Generation)
用途:通过批量提示词节点或通配符节点,一次运行生成多张不同内容的图片。可配合Dynamic Prompts自定义节点实现高级批量控制。
适用场景:A/B测试提示词、批量素材生成、灵感发散探索。
| 参数 | 推荐值 |
|---|---|
| 批量大小 | 2-8(根据显存) |
| 提示词列表 | 每行一个 |
| 种子模式 | 随机 / 固定 |
| 输出目录 | 指定独立文件夹 |
15. Img2Img + ControlNet 复合工作流
用途:终极控图方案——同时使用参考图的像素信息(图生图)和结构信息(ControlNet),实现最大的创作自由度与控制精度的平衡。
适用场景:高质量风格迁移、商业级图片生成、设计稿转渲染图。
| 参数 | 推荐值 |
|---|---|
| Denoise | 0.5-0.7 |
| ControlNet类型 | Canny + Depth 双控 |
| 各自强度 | 0.6-0.8 |
| 起点/终点 | 0.1/0.9 |
工作流去哪儿找?
除了本文整理的15个工作流模板,下面这些平台也是找ComfyUI工作流的好去处:
- Civitai:搜索”ComfyUI workflow”,海量免费工作流附带预览图和评分,是目前最大的社区来源。
- OpenArt:提供在线ComfyUI运行环境和大量精选工作流,支持一键导入到本地。
- ComfyUI官方GitHub:
comfyanonymous/ComfyUI_examples有官方示例,适合学习标准节点用法。 - 国内社区:LiblibAI、吐司等平台也有大量中文用户分享的ComfyUI工作流。
建议优先选择评分高、更新日期近、有预览图的工作流,避免下载到年代久远已经失效的旧版工作流。
加载工作流遇到报错怎么办?
即使从可靠来源下载的工作流,也可能因为你的本地环境不同而报错。以下是快速排障流程:
- 缺少自定义节点(最常见):安装ComfyUI Manager,点击”Install Missing Custom Nodes”一键补齐。
- 模型路径不匹配:检查工作流中Load Checkpoint/LoRA等节点的模型名称,确保你的
models文件夹中有对应文件,或者修改节点选择本地已有的模型。 - ComfyUI版本过旧:某些新节点需要较新版本的ComfyUI,执行
git pull更新到最新版。 - 自定义节点冲突:一次只安装一个缺失节点,定位到冲突源后卸载或更换替代节点。
大多数情况下,ComfyUI Manager的”一键修复”功能就能解决90%的报错问题。
总结
ComfyUI的工作流就像程序员的代码库——站在别人的肩膀上,永远比自己从零造轮子快得多。本文介绍的15个工作流模板覆盖了文生图、图生图、精准控制、放大修复、视频生成和批量处理等主要场景,导入后换上你的模型和提示词即可使用。
如果你是AI绘画新手,建议从**工作流1(最简文生图)**先跑通整个流程,再逐步尝试ControlNet和放大类工作流。更多ComfyUI和Stable Diffusion的深度教程,可以参考:
本文所有工作流JSON文件可从Civitai和OpenArt平台获取对应名称的最新版本。
进阶技巧:让工作流效率再翻倍
用了几个月ComfyUI之后,我总结出几个真正管用的进阶技巧,分享给你。
技巧1:善用Group Node整理画布。 当工作流节点超过20个时,画布会变得混乱。用Ctrl+G把相关节点打包成组,标注名称(比如”预处理”、“采样”、“后处理”),后期调试效率提升至少40%。我自己每个工作流都严格按”输入→处理→输出”三段分组。
技巧2:用Primitive Node统一管理参数。 把分辨率、CFG、步数这些经常调整的参数抽出来,连到一个Primitive Node上。这样改一个值就能同步到所有相关节点,不用一个个去找。特别是做A/B测试的时候,这个技巧能省下大量时间。
技巧3:Seed固定+提示词变量法。 先用固定Seed找到一张满意的构图,然后只改提示词中的风格描述词,保持其他参数不变。这样能快速测试不同风格效果,而不用每次都重新跑构图。我一般固定3-5个Seed值作为”基准构图库”。
| 技巧 | 适用场景 | 效率提升 |
|---|---|---|
| Group Node | 复杂工作流 | 调试效率+40% |
| Primitive Node | A/B测试参数 | 修改效率+60% |
| Seed固定法 | 风格探索 | 出图效率+50% |
| 工作流版本管理 | 长期项目 | 回溯效率+80% |
| 预览节点插入 | 过程监控 | 排错效率+70% |
技巧4:插入Preview Image节点做过程监控。 在每个关键步骤后面都加一个Preview Image节点,这样能实时看到每一步的处理结果。出了问题时立刻定位是哪一步的毛病,不用等全部跑完才发现不对。
技巧5:用Note节点记录参数笔记。 每次调到满意的效果,立刻用Note节点把参数记下来。三个月后你回头看,这些笔记比任何教程都值钱。我自己已经积累了200多条参数笔记,覆盖了几十个模型和LoRA的最佳配置。
更多实战场景补充
商业级电商产品图工作流
做电商产品图是ComfyUI最高频的商业场景之一。我搭建了一套完整的产品图工作流:先用ControlNet Depth控制产品轮廓,再用Inpainting替换背景,最后用Ultimate SD Upscale放大到4K输出。整个流程20分钟出一张,传统PS修图至少要2小时。
关键参数方面,ControlNet强度设在0.75-0.85之间最稳,太高会丢失产品细节,太低则背景融合不自然。Inpainting的降噪强度建议0.6-0.7,这个区间背景替换最干净。
人像写真批量化工作流
如果你想用ComfyUI做AI写真,核心是InstantID加IP-Adapter的组合。先用InstantID锁定人脸特征(权重0.85),再用IP-Adapter控制整体风格(权重0.6),配合不同的LoRA风格模型,一套工作流能出20种不同风格的写真。我帮朋友做了一套,20张不同风格的写真从拍摄到出图只用了45分钟。
如果你对AI绘画的整体生态还不太了解,建议先看看Stable Diffusion和AI绘画工具推荐,建立起全局认知后再深入ComfyUI。想要用AI绘画赚钱的朋友,可以参考AI绘画变现方法和免费AI工具推荐。
动态LoRA切换技巧
一个高级玩法是在同一个工作流中串联多个LoRA,通过控制每个LoRA的起止步数来实现风格渐变效果。比如前50%步数用写实LoRA,后50%步数用油画LoRA,出来的图就有写实转油画的梦幻效果。这个技巧在社交媒体上特别吸引眼球。
常见问题与排障指南
工作流加载后节点变红怎么办
节点变红说明你缺少对应的自定义节点。最快的解决办法是安装ComfyUI Manager,打开后点击Install Missing Custom Nodes,它会自动识别缺失的节点并一键安装。90%的情况下这一步就能解决问题。
如果Manager也找不到某个节点,说明这个工作流用了非常小众的插件。这时候有两个选择:要么去GitHub手动搜索安装,要么换一个类似功能但更通用的工作流替代。
显存不足怎么优化
显存不够时有几个立竿见影的办法。第一,降低生成分辨率,先用512x512出图再放大。第二,启用VAE Tiling(在VAE Decode节点设置里勾选)。第三,用FP16半精度加载模型(显存减半)。第四,关闭不用的Preview节点(它们也占显存)。
我用RTX 3060 12GB跑SDXL工作流时,通过以上优化可以稳定出1024x1024的图。如果你的显卡只有8GB显存,建议用SD1.5模型配合Hires Fix工作流,效果也不差。
如何让工作流跑更快
速度优化主要从三个方面入手。采样步数从30降到20(质量损失很小但速度快30%)。用LCM LoRA加速采样(只需4-8步即可出图)。开启xformers注意力优化(减少显存占用的同时提速10-15%)。批量生成时把batch_size设为2-4(比逐张生成快,但需要更多显存)。
工作流资源推荐与学习路径
对于想要深入学习ComfyUI工作流的朋友,我推荐以下学习路径。第一阶段(1-2周):跑通最简文生图工作流,理解Checkpoint、CLIP、KSampler、VAE四个核心节点的作用和连接关系。第二阶段(3-4周):学习图生图和ControlNet工作流,掌握降噪强度和预处理器的调节方法。第三阶段(2-3个月):学习高级工作流编排,包括AnimateDiff视频生成、IP-Adapter风格迁移、多LoRA叠加等进阶技巧。
推荐学习资源:ComfyUI官方GitHub的examples目录有标准示例,Civitai上有大量社区分享的工作流(按评分排序选择),B站搜索ComfyUI教程有大量中文教学视频。最重要的还是多动手实践——每学一个新技巧,立刻在你的工作流里试一试,比看十遍教程都有用。
另外建议大家加入ComfyUI的中文社区(如LiblibAI论坛和吐司社区),遇到问题可以在社区里提问,很多资深用户会热心解答。我自己就是在社区里学到了很多书本上学不到的实战经验。
我的个人工作流收藏清单
最后分享几个我自己日常使用频率最高的工作流。第一个是产品图工作流(ControlNet Depth加Inpainting加Upscale),每周至少用10次以上,是商业项目的主力。第二个是LoRA测试工作流(多LoRA加Grid输出),用来快速筛选新下载的LoRA哪个效果最好。第三个是AnimateDiff短视频工作流,做社交媒体动态内容特别高效。
这些工作流我都做了详细的参数笔记和版本管理,每次升级ComfyUI或者换模型后都会重新校准一遍。建议大家也养成这个习惯,好的工作流是经过无数次调试才稳定下来的,一旦丢失重头来过的代价太大了。
补充一点:如果你在使用工作流的过程中遇到了问题,不要一个人闷头研究。ComfyUI社区非常活跃,你遇到的问题99%都有人解答过。在GitHub的Issues页面搜索关键词,或者在Reddit的ComfyUI板块发帖提问,通常24小时内就能得到回复。另外建议关注几个ComfyUI的大佬账号(如comfyanonymous本人),他们经常分享最新的工作流技巧和节点用法说明。
深度扩展阅读
本文涵盖的内容是AI领域持续发展的方向之一。如果想进一步了解相关知识,可以参考以下推荐阅读:
相关工具推荐
以下是本文提到或相关的AI工具,点击即可查看详细介绍:
-
LocalBanana:一个专注于AI图像提示词收集与结构化的工作空间,帮助用户通过参考图像、场景或想法高效生成视觉内容。
-
蚂上有创意:蚂上有创意是支付宝官方推出的AI智能营销设计平台,为商家提供商品图生成、海报制作、图像处理及创意诊断等一站式服务,旨在通
-
Canva可画:Canva可画是一款集成AI写作、绘画、修图等功能的一站式智能设计工具平台,旨在提升设计与内容创作效率。
-
灵光AI:蚂蚁集团推出的全模态通用AI助手,支持自然语言交互、快速生成小应用及多端同步。
推荐阅读
- ComfyUI工作流下载分享:ComfyUI工作流下载分享:10个高质量免费工作流推荐
- 专业级AI图像生成:2026年ComfyUI高级工作流教程:专业级AI图像生成实战
- AI绘画工作流工具从零入门:ComfyUI完整教程:2026最强AI绘画工作流工具从零入门
- ComfyUI进阶工作流教程:ComfyUI进阶工作流教程