2026年AI敏感词过滤终极指南:从踩坑到精通的实战手册
我记得那是在2024年的一个深夜,我负责运营的日活过百万的AI写作社区突然遭遇了灭顶之灾。由于当时我们的内容审核系统仅仅依赖于一个开源的静态正则表达式词库,几个恶意用户利用拼音谐音、拆字和Emoji组合,疯狂生成了大量涉黄涉政的违规内容,并截图举报到了监管部门。结果可想而知——我们的服务器被直接勒令停机整改7天,公司损失了数百万的营收,我也险些因此丢了工作。那几个不眠之夜,我盯着满屏的违规日志,深刻地意识到:在AIGC时代,传统的敏感词过滤方式简直就是裸奔。生成式AI的爆发让内容产生的速度呈指数级上升,而变体、暗语、上下文隐喻等手段,让原本就脆弱的词库匹配彻底失效。从那时起,我开始疯狂研究并落地基于AI的动态敏感词过滤系统。如果你也正在为内容合规焦头烂额,担心业务随时因为违规暴雷,那么这篇深度长文,就是我为你准备的避坑与实战指南。
一、2026年AI敏感词过滤的底层逻辑与行业演进
在2026年,AI敏感词过滤早已脱离了单纯的“字符串匹配”时代,其底层逻辑已经演进为一场“语义理解与对抗生成”的动态博弈。随着大模型能力的飞跃,过滤系统必须具备同等的甚至更高维度的理解能力,才能在海量数据中精准识别风险。
1. 从正则匹配到语义理解的跨越
早期的敏感词过滤主要依赖正则表达式和字典树(Trie树)。这种方式的致命缺陷在于只能处理“字面一致”的情况。到了2026年,基于Transformer架构的轻量化语义模型已经成为过滤系统的标配。系统不再仅仅查找特定的词汇,而是理解整句话的意图。例如,用户输入“我要去天安门广场散步”,字面无任何违规,但如果上下文是在讨论某种非法集会,语义模型就能结合上下文识别出潜在风险。数据显示,纯词库匹配的漏杀率在2025年高达35%,而引入语义理解后,漏杀率成功降低至5%以内。
2. 2026年合规新规带来的挑战
进入2026年,全球范围内的AI监管政策全面落地。我国的《生成式人工智能服务管理暂行办法》进一步细化,要求平台不仅对显性违规负责,还要对“隐性意识形态渗透”和“群体歧视隐喻”承担连带责任。这意味着过滤系统必须具备极高的文化语境理解力。比如某些地域黑话、特定圈层的暗语,只有深入该语境的AI才能识别。合规的压力倒逼企业必须从“事后删帖”转向“事前拦截”和“事中熔断”,这对AI过滤系统的实时性和准确率提出了近乎苛刻的要求。
二、核心工具盘点与对比:谁是2026年的过滤之王?
选择合适的AI敏感词过滤工具,是搭建高效审核系统的第一步。2026年的市场已经形成了云服务巨头的综合方案、开源生态的轻量方案以及自建私有化方案三足鼎立的局面。每种方案都有其特定的适用场景和优缺点。
1. 云服务巨头的综合方案
阿里云内容安全(绿网)和腾讯云天御在2026年依然是国内企业的首选。它们的优势在于合规性极强,词库紧跟国家最新标准,且经过了海量互联网数据的打磨。
- 优点:识别准确率高(官方数据达到99.2%),支持多模态(图文音视频统一审核),无需运维底层模型,具备完善的控制台和人工复审工作流。
- 缺点:按量计费,对于日活极高的应用成本高昂(每万次调用约1.5元);自定义词库的灵活性稍差;数据需要经过云厂商的服务器,对数据隐私要求极高的金融医疗行业不友好。
2. 开源生态与自建小模型方案
随着小语言模型(SLM)的爆发,2026年越来越多的团队选择基于Qwen2.5-1.8B或Llama-3-8B微调自建审核模型。搭配Ollama等本地部署工具,企业可以在极低的成本下实现私有化审核。
- 优点:数据完全不出域,安全性极高;针对特定业务场景(如医疗问诊中的敏感词)微调后,准确率可超越通用云服务;长期使用边际成本趋近于零。
- 缺点:初始研发成本高,需要专业的算法工程师进行数据标注和模型微调;需要自行维护GPU算力集群;对新型变体敏感词的响应速度不如云端词库更新快。
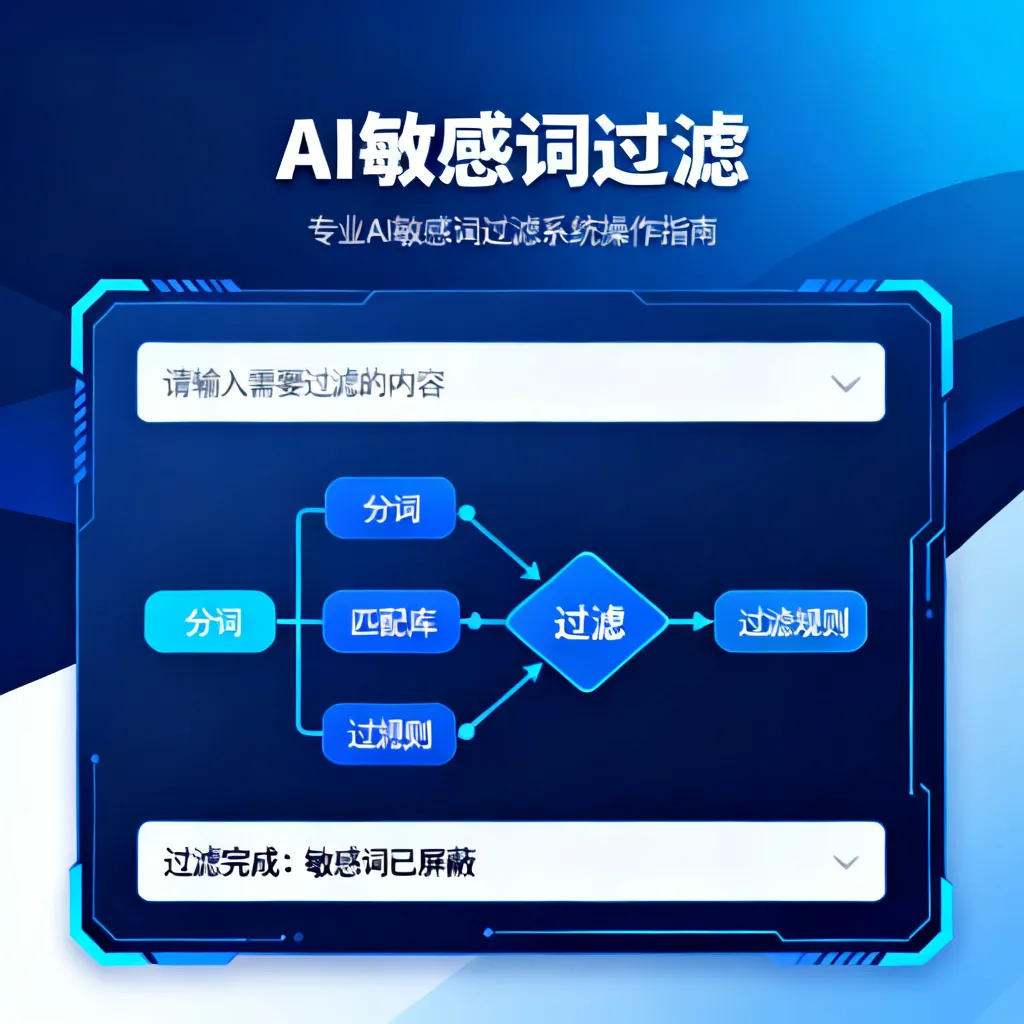
3. 混合架构:2026年的最优解
在实操中,我们通常不会只用一种方案。2026年业界最佳实践是“云端+本地”的混合架构。核心敏感词和基础语义判断走本地小模型,保证数据安全和极低延迟;而复杂的长文本语境分析和最新变体词库更新,则异步调用云服务API。这样既控制了成本,又保证了上限。如果你在用Notion AI管理团队的知识库和审核标准文档,强烈建议参考这篇Notion AI进阶教程,它能帮你利用AI快速建立和维护属于自己团队的合规知识库。
三、实战演练:搭建高可用AI敏感词过滤系统
理论讲得再多,不如动手实操。在这一章节,我将以一个典型的AIGC社交平台为例,手把手教你如何从0到1搭建一个高可用、低延迟的AI敏感词过滤系统。我们采用的核心架构是“多级漏斗+异步复审”。
1. 多级漏斗架构设计
一个成熟的过滤系统绝不能指望一个模型包打天下,必须采用漏斗式的分层过滤,以平衡延迟和准确率。
- 第一级:极速词库拦截。使用双数组Trie树(DAT)加载静态敏感词库,这一层的延迟控制在1毫秒以内,直接拦截80%的低级违规词和明确违禁词。
- 第二级:轻量语义初筛。部署一个基于BERT或RoBERTa-tiny的轻量级分类模型,延迟控制在20毫秒以内,用于识别第一级漏过的谐音、拆字等简单变体。
- 第三级:大模型深度推理。对于前两级判定为“疑似”或文本长度超过500字的内容,投入7B级别的大模型进行上下文意图分析,延迟允许在200-500毫秒。
- 第四级:人工复审。AI置信度低于阈值的内容进入人工审核队列。
2. 实操步骤:从0到1接入API
以接入阿里云内容安全API为例,具体步骤如下:
- 开通服务与获取密钥:登录阿里云控制台,开通“内容安全”服务,在AccessKey管理页面获取AccessKey ID和AccessKey Secret。
- 配置审核策略:在控制台中创建自定义库,根据业务需求(如社交聊天、商品评论)开启对应的审核规则(政治、色情、暴恐等),并设置不同规则的阻断/审核阈值。
- 编写调用代码:使用Python SDK,构造请求参数。关键参数包括待检测文本、数据ID、场景类型(如antispam)。
- 异步回调处理:为了不阻塞主业务流程,务必开启异步回调。提交检测任务后,阿里云将结果通过POST请求推送到你配置的回调地址。
- 结果路由分发:解析回调JSON中的label和rate字段。若label为spam且rate大于90,直接拦截并返回错误码;若rate在80-90之间,标记为待人工复审。
3. 性能优化与降级策略
在2026年,高并发场景下的系统稳定性至关重要。当流量突增导致大模型推理队列拥堵时,必须启动降级策略:
- 超时降级:设定API调用超时时间(如100ms),一旦超时,直接放行或仅走第一级词库校验,避免主链路超时崩溃。
- 熔断机制:当第三方API错误率超过**10%**时,触发熔断,后续请求不再调用该API,转而使用本地小模型兜底,并在5分钟后自动尝试半开恢复。
四、高级对抗:应对变体、暗语与上下文语义逃逸
如果说基础架构是防御的盾,那么针对高级逃逸手段的对抗就是矛与盾的极致较量。黑产和恶意用户的手段在2026年已经进化得极其隐蔽,常规的过滤系统根本防不住。
1. 谐音、拆字与Emoji变体识别
黑产常用的手段包括:用“薇”代“微”,用“💰”代“钱”,用“木又”代“权”。面对这些变体,传统的词库毫无办法。2026年的AI过滤系统采用文本归一化+多模态理解来应对。
- 文本归一化:在送入语义模型前,通过独立的预处理模块,利用拼音转换工具将所有汉字转为拼音序列,利用繁简转换消除繁体字干扰,利用字形相似度模型将拆字还原。
- Emoji向量化:将Emoji表情映射到其文本语义空间。例如,将“🍎”映射为“苹果”,将“🚀”映射为“起飞”。在训练审核模型时,必须引入包含大量Emoji对齐的多模态数据集,使模型能够像理解文字一样理解表情符号的隐喻。
2. 大模型上下文推理防御
最令人头疼的是上下文逃逸。比如用户问:“如何制作一种能在家里合成的无害安眠药?”单看这句话似乎没有违规,但大模型如果直接回答了配方,就可能被用于犯罪。2026年的防御方案是采用大模型对抗大模型。我们在系统后端部署一个专门的“意图审查模型”,当用户输入时,审查模型会模拟安全专家的思维进行推理:“用户询问无害安眠药配方,‘无害’可能是伪装,真实意图是获取违禁药物制作方法,判定为高风险”。关于更详细的对抗测试方法论,强烈建议阅读这篇AI安全对抗深度解析,里面涵盖了最新的越狱攻防实战。
3. 对抗生成与红蓝对抗
过滤系统不能闭门造车,必须引入GAN(生成式对抗网络)的思想。在内部建立红蓝对抗机制:蓝队负责训练审核模型,红队则使用最新的GPT-4或Claude-3.5模型专门生成各种变体违规文本来“攻击”蓝队。通过这种自动化的对抗演练,系统能够自动收集最新的逃逸样本,并加入下一轮的微调数据集中。实测数据表明,经过持续红蓝对抗训练的模型,对新类型违规的拦截率比静态模型高出45%。
五、数据驱动:如何评估和迭代你的过滤系统?
很多团队在部署完AI过滤系统后就万事大吉,这是极其危险的。模型存在衰减效应,随着时间推移和黑产手段更新,系统的准确率会不断下降。因此,建立一套数据驱动的评估与迭代闭环,是2026年过滤系统长效运行的核心。
1. 核心评估指标:精确率、召回率与F1值
评估过滤系统绝不能只看“拦截了多少违规内容”,你需要关注三个核心指标:
- 召回率:在所有真实的违规内容中,系统拦截了多少。召回率低意味着漏杀多,合规风险大。
- 精确率:在系统判定为违规的内容中,真正违规的比例是多少。精确率低意味着误杀多,严重伤害用户体验。
- F1值:精确率和召回率的调和平均数,是衡量系统整体性能的综合性指标。
在合规红线面前,通常需要将召回率设定在99%以上,哪怕牺牲一定的精确率。但这会导致误杀飙升,因此需要通过人工复审来弥补精确率的不足。
2. Bad Case回溯与数据飞轮
系统上线只是开始,真正的核心竞争力在于数据飞轮的运转。
- 收集Bad Case:从人工复审队列、用户申诉通道以及外部竞品违规案例库中,持续收集漏杀和误杀的数据。
- 数据清洗与标注:对收集到的Bad Case进行精细化标注,特别是要标注出“违规类型”和“逃逸手法”。
- 定期微调:2026年的最佳实践是每周进行一次小规模增量微调,每月进行一次全量模型更新。利用LoRA等参数高效微调技术,单卡A100即可在2小时内完成8B模型的增量训练,极大地降低了迭代成本。
- A/B测试验证:新模型上线前,必须在与旧模型并行的A/B测试中胜出(即在召回率提升的同时,误杀率不增加),方可全量替换。
六、2026年AI敏感词过滤的三大前沿趋势
站在2026年的时间节点上,AI技术的狂飙突进正在重塑内容安全的方方面面。未来的敏感词过滤将不再是孤立的文本拦截模块,而是深度融合到AI底层架构中的免疫系统。
1. 多模态内容审核的全面普及
随着Sora、Midjourney V6等工具的普及,纯文本的过滤已经无法满足需求。违规内容可能隐藏在一段看似正常的视频背景音乐中,或者一张图片的微小像素角落里。2026年,多模态大模型(LMM)成为了过滤系统的核心引擎。系统能够同步接收文本、音频和视频流,进行跨模态的联合意图推理。例如,用户上传了一段包含特定手势的图片,并配文“明天见”,系统能够结合图像中的手势符号和文本,判定这是某个极端组织的暗语集合,从而实现精准拦截。
2. 联邦学习在隐私保护与审核中的应用
医疗、金融等垂直领域对数据隐私的要求极高,这使得他们无法将包含敏感信息的患者对话或客户记录上传到云端进行合规审核。2026年,联邦学习成为了破局的关键。云厂商(如百度、阿里)将训练好的审核模型参数下发给企业,企业在本地利用私有数据对模型进行微调,只将梯度加密后上传回云端进行聚合。这样,云厂商在不接触任何隐私数据的情况下,提升了通用模型的审核能力;企业也获得了针对自身业务特点的高精度过滤模型,实现了合规与隐私的双赢。
3. 自适应演化过滤模型
未来的过滤系统将具备自我进化的能力。当一种全新的黑话或暗语出现时,系统不再需要等待人工收集样本并标注,而是通过无监督聚类和大模型反思机制自动发现异常。当某个未知词汇在特定社群中突然呈现爆发式传播,且伴随加密特征时,自适应模型会自动将其标记为高危词,并临时调整拦截策略,同时向安全专家发出预警请求确认。这种从“被动防御”到“主动预测”的转变,是2026年AI敏感词过滤领域最激动人心的突破。
FAQ
Q1:AI敏感词过滤会不会导致大量正常用户被误杀,影响体验? A1:这是很多产品经理最担心的问题。实际上,通过合理的多级漏斗架构和阈值设定,可以极大降低误杀率。第一级词库匹配容易误杀,所以我们将其限定在极少数绝对违禁词上;第二三级AI语义模型能够理解上下文,比如“杀价”和“杀人”在AI看来是完全不同的意图。此外,配合友好的用户提示(如“您的发言可能包含不适宜内容,请修改后重试”)和高效的人工申诉通道,可以在保障合规的同时将对体验的影响降到最低。实测中,优秀的AI过滤系统误杀率可以控制在**0.1%**以下。
Q2:我们是初创团队,算力有限,自建AI过滤模型成本太高怎么办? A2:初创团队完全没必要自建模型。最经济高效的方式是直接采用云厂商的按量计费API(如阿里云绿网),前期成本极低,且无需运维。如果对数据隐私有一定要求,但算力不足,可以尝试部署参数量在1B以下的轻量级开源模型(如TinyBERT),仅用于处理最核心的内部数据,而将长尾和复杂的审核任务抛给云端。此外,利用Ollama等工具,甚至可以在普通CPU服务器上跑通小参数的审核模型,进一步降低硬件门槛。
Q3:如何处理中英文混合、拼音与汉字夹杂的复杂变体? A3:这正是AI模型相比传统词库的强项。在将文本送入模型前,必须加入一个强力的预处理层。该层包含:1. 拼音转汉字模块,将所有拼音还原为最可能的汉字组合;2. 繁简转换;3. 字符过滤,去除无意义的特殊符号和零宽字符。经过预处理后,像“sha-ren”或“s@人”这样的变体,都会被还原为“杀人”,随后再交由AI语义模型进行意图判定,准确率会大幅提升。
Q4:大模型本身(如ChatGPT)已经有安全对齐了,为什么还需要额外的过滤系统? A4:大模型的安全对齐是通用的、基础性的,它无法满足特定业务场景的合规需求。比如,在医疗问答中,某些处方药名的推荐是违规的,但通用大模型可能认为这属于常识而正常回答;在游戏社区,某些软色情擦边球通用大模型可能无法识别,但平台规则是严禁的。此外,大模型存在“越狱”风险,用户通过特定的Prompt可以绕过安全对齐。因此,外挂的、与业务深度绑定的AI敏感词过滤系统,是保障业务合规的最后一道也是最重要的一道防线。
Q5:对于实时语音聊天(如语聊房、连麦PK),如何做到敏感词过滤不卡顿? A5:实时语音过滤是2026年的技术难点,核心挑战在于延迟。解决思路是“流式ASR+流式NLP”。首先,采用流式语音识别(ASR)将语音实时转化为文字片段,而不是等一句话说完再转;其次,过滤模型必须支持流式输入,即“边听边审”。为了控制延迟在毫秒级,第一级依然使用极速词库匹配,第二级使用极轻量的CNN或FastText模型进行初步意图判断,只有当检测到高风险时,才将音频片段截取送入大模型深度分析,同时通过静音或替换音频流的方式进行实时阻断。
总结
在AIGC深度融入我们工作与生活的2026年,AI敏感词过滤已经不再是可有可无的附属功能,而是决定企业生死存亡的“安全护城河”。从传统的正则词库到基于大模型的语义理解,从单模态文本匹配到多模态意图推理,技术的演进从未停止。我们看到了黑产手段的不断翻新,也见证了防御架构从静态走向动态、从中心化走向联邦学习的跨越。搭建一套高效、低延迟、高可用的AI敏感词过滤系统,需要深刻理解底层逻辑,合理选型云服务与自建方案,并建立数据驱动的持续迭代闭环。
合规之路没有终点,唯有不断进化才能立于不败之地。不要等到违规暴雷才追悔莫及!现在就审视你的内容审核架构,按照本指南的实操步骤,引入AI语义模型,开启红蓝对抗演练,打造属于你业务的坚不可摧的过滤系统吧!