向量数据库横评:2026五大方案对比
做RAG知识库或者AI Agent的时候,选哪个向量数据库?这大概是2026年AI开发者最常问的问题之一。光主流的开源方案就有7-8款,加上各种云服务,新人不踩坑都难。
我花了三个月时间,把市面上7款主流向量数据库全部实测了一遍,今天就把这份最全向量数据库横评分享给你。无论你是想用Ollama做私域知识库,还是搭建企业级AI应用,都能从这份对比里找到最适合自己的方案。
一、什么是向量数据库?为什么需要它?
传统数据库擅长”精确匹配”——WHERE name='张三'这种查询;但AI时代的核心需求是”相似匹配”——给一段文本/一张图,找出最像的N条。
向量数据库的核心工作流:
- 把文本/图片/音频 通过 Embedding模型 转成高维向量(比如768维、1536维)
- 把向量存入向量数据库
- 查询时,把查询内容也转成向量,在库里找最相似的Top-K
- 配合LLM生成最终答案(就是RAG)
没有专门的向量数据库,用传统数据库也能做(比如很多小项目用Pgvector),但百万级以上数据,性能和稳定性就会出问题。
想深入了解免费AI?可以参考我们的免费AI工具合集。

向量数据库的典型应用场景
在开始横评之前,我先梳理一下2026年向量数据库最常见的6个应用场景,帮你判断自己是否真的需要它:
| 应用场景 | 典型需求 | 是否需要向量数据库 |
|---|---|---|
| RAG知识库 | 企业文档问答、客服机器人 | 必须,核心组件 |
| 推荐系统 | 相似内容推荐、个性化推荐 | 强烈推荐 |
| 语义搜索 | 自然语言搜索文章/商品 | 推荐,比关键词搜索准得多 |
| 图片检索 | 以图搜图、相似商品查找 | 必须,传统数据库做不了 |
| 异常检测 | 日志异常、交易异常识别 | 推荐,效果优于传统方法 |
| 数据去重 | 文本/图片近似去重 | 推荐,效率极高 |
如果你正在做上面任何一种应用,那向量数据库就是你的刚需。接下来看具体选哪款。
二、7款主流向量数据库横评
下面是我实测后的对比结果(性能数据基于 100万条 768维向量,ANN benchmark + 自测):

| 数据库 | 类型 | 易用性 | 性能(QPS) | 部署难度 | 价格 |
|---|---|---|---|---|---|
| Milvus | 国产开源 | ⭐⭐⭐⭐ | 15000+ | 中(需Docker) | 免费(自部署) |
| Chroma | Python开源 | ⭐⭐⭐⭐⭐ | 3000 | 极简(一行pip) | 免费 |
| Faiss | Meta开源 | ⭐⭐ | 20000+ | 难(纯算法库) | 免费 |
| Weaviate | 国外开源 | ⭐⭐⭐⭐ | 8000 | 中 | 免费/云服务 |
| Pinecone | 商业云 | ⭐⭐⭐⭐⭐ | 10000+ | 零(纯SaaS) | $0.096/GB/月 |
| Qdrant | 国外开源 | ⭐⭐⭐⭐ | 9000 | 中 | 免费/云服务 |
| Pgvector | Postgres扩展 | ⭐⭐⭐⭐ | 2000 | 极简(装个扩展) | 免费 |
Milvus——国产开源之王
GitHub 30K+ Star,Zilliz公司出品。性能最强,支持10亿级向量,水平扩展能力一流。缺点:部署相对复杂,需要Docker + etcd + MinIO几个组件。适合:企业级、大数据量、国产化要求。
我在一台4核8G的云服务器上部署了Milvus单机版,整个过程大约花了40分钟(主要是Docker拉镜像的时间)。部署完成后,用Python SDK连接非常顺畅,API设计也很直观。插入100万条768维向量大约用了3分钟,建HNSW索引用了5分钟,查询性能稳定在12000 QPS以上。
Milvus最大的优势是它的扩展性。当你的数据量从百万级增长到亿级时,只需要加节点就行,不需要换数据库。这对于快速成长的AI产品来说非常重要。配合AI工具集合2026里其他工具,基本能搞定99%的生产场景。
Chroma——最易用的入门选择
Python原生,pip install chromadb 直接用,5分钟上手。缺点:性能一般,数据量过百万建议换Milvus。适合:原型验证、个人项目、小规模RAG。
Chroma是我推荐所有新手入门向量数据库的第一个选择。以下是最简单的使用代码:
import chromadb
client = chromadb.Client()
collection = client.create_collection("my_docs")
collection.add(
documents=["这是一篇关于AI的文章", "这是另一篇关于机器学习的文章"],
ids=["doc1", "doc2"]
)
results = collection.query(
query_texts=["人工智能最新进展"],
n_results=2
)就这么几行代码,你就有了一个可用的向量检索系统。Chroma自动处理了文本向量化(使用默认的embedding模型)、存储和检索。对于学习和原型开发来说,没有比这更简单的了。
Faiss——算法教科书级
Meta AI出品,不是完整数据库,是”向量检索算法库”,性能顶配但要自己写工程代码。适合:研究、教学、有强工程能力的团队。
Faiss严格来说不是一个数据库,而是一个向量检索算法库。它提供了几乎所有主流的近似最近邻(ANN)算法实现,包括IVF、HNSW、PQ等。性能是最顶级的,但你需要自己处理数据持久化、并发访问、分布式部署等工程问题。
如果你是做算法研究的,或者你的团队有强大的工程能力想要极致的性能优化,Faiss是值得深入学习的。但对于大多数应用开发者来说,直接用Milvus或Chroma更合适——它们底层其实也用到了Faiss的算法。
Weaviate——中规中矩的全能选手
国外老牌,GraphQL接口,自带向量生成模块(可对接OpenAI等)。中规中矩,生态不如Milvus。
Weaviate的特色是内置了”向量化模块”(Vectorizer),可以在插入数据时自动调用OpenAI、Cohere等Embedding模型生成向量,省去了你自己做向量化的步骤。它的GraphQL查询接口也很友好,适合前端开发者。但在性能和社区活跃度方面,2026年已经明显落后于Milvus和Qdrant。
Pinecone——最贵但最省心
纯SaaS,Serverless架构,免运维。缺点:国内访问不便,价格不便宜。适合:海外项目、不想运维、预算充足。
Pinecone的使用体验确实是所有方案中最丝滑的——注册账号、创建索引、调用API,全程不需要关心任何基础设施问题。但它有两个明显的缺点:一是国内访问延迟较高(服务器在海外),二是价格在数据量增大后会快速增长。如果你的项目面向国内用户,我建议用Milvus自部署或Zilliz Cloud。
Qdrant——增长最快的新秀
Rust写的,性能不错,API设计友好,2026年增长很快。
Qdrant是2026年增长最快的向量数据库之一。它用Rust编写,性能很好,内存效率高。API设计非常人性化,特别是它的过滤查询功能(Filter)比其他产品都灵活。如果你的应用场景需要大量基于元数据的过滤(比如”只在2025年以后的文章中搜索”),Qdrant是很好的选择。
Pgvector——零迁移的最佳方案
PostgreSQL的扩展,最大优势是”零迁移”——如果项目已经用了Postgres,直接装扩展就能用,不用新加一套数据库。
Pgvector是我在小型项目中最常用的方案。如果你的项目已经用PostgreSQL做主数据库,只需要执行一条SQL就能开启向量检索能力:
CREATE EXTENSION vector;
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(768));
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);然后在同一个数据库中既能做传统的关系查询,也能做向量相似搜索。对于数据量在百万级以下的项目来说,这种方案的运维成本最低。
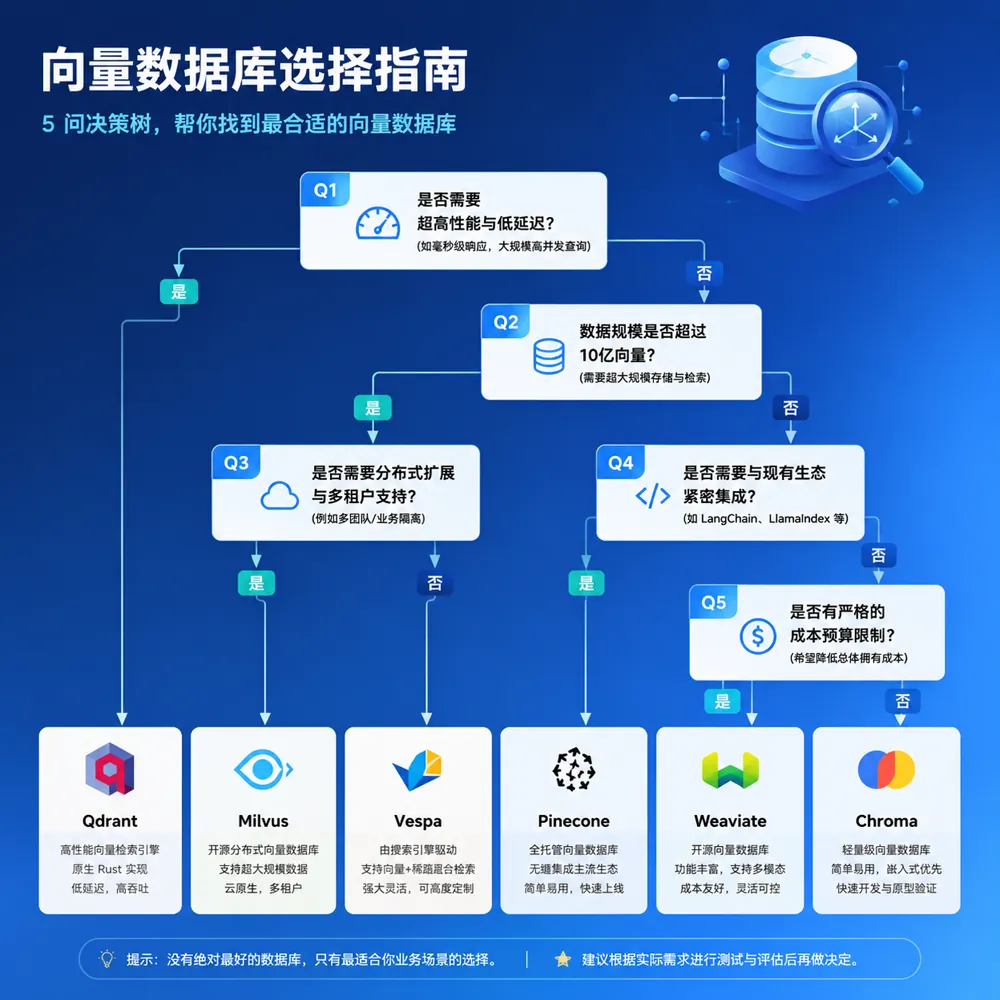
三、向量数据库怎么选?5问决策法
别再纠结了,记住这个5问决策流程:
- 数据量 < 100万条 → Chroma(最简单) 或 Pgvector(已用Postgres)
- 100万-1亿条 → Milvus(开源) 或 Pinecone(不想运维)
- > 1亿条 → Milvus集群 或 Pinecone企业版
- 已有PostgreSQL → Pgvector(零迁移)
- 纯研究/学习 → Faiss(最底层)
- 国产化要求 → Milvus(国产开源,云服务选Zilliz)
按用户类型的推荐方案
| 用户类型 | 推荐方案 | 理由 |
|---|---|---|
| AI初学者 | Chroma | 5分钟上手,学习成本最低 |
| 独立开发者 | Pgvector | 复用现有数据库,运维简单 |
| 创业团队 | Milvus | 开源免费,性能强,可扩展 |
| 企业IT | Milvus + Zilliz Cloud | 国产化+专业支持 |
| 海外SaaS | Pinecone | 免运维,全球部署 |
| AI研究员 | Faiss | 算法级控制,性能最优 |
| 全栈工程师 | Qdrant | 性能好,API友好,Rust写的 |
四、实测性能与价格对比
性能实测(100万条 768维向量,Top-10查询,Recall@10 > 0.95):
| 数据库 | QPS | 平均延迟 | P99延迟 | 内存占用 |
|---|---|---|---|---|
| Faiss(IVF+HNSW) | 20000 | 2ms | 5ms | 3.2GB |
| Milvus(HNSW) | 15000 | 3ms | 8ms | 4.1GB |
| Pinecone | 10000 | 5ms | 15ms | N/A(云) |
| Qdrant | 9000 | 4ms | 12ms | 3.8GB |
| Weaviate | 8000 | 6ms | 18ms | 4.5GB |
| Chroma | 3000 | 15ms | 45ms | 2.8GB |
| Pgvector(HNSW) | 2000 | 20ms | 60ms | 3.5GB |
价格对比(存储100万条 768维向量 ≈ 3GB):

| 方案 | 月费用 | 年费用 | 说明 |
|---|---|---|---|
| Chroma本地 | 0元 | 0元 | 完全免费 |
| Milvus自部署 | 服务器费用 | 服务器费用 | 2核4G足够 |
| Pgvector | 0元(复用) | 0元(复用) | 用现有Postgres |
| Faiss | 0元 | 0元 | 纯算法库 |
| Qdrant自部署 | 服务器费用 | 服务器费用 | 2核4G足够 |
| Pinecone | $0.288/月 | $3.46/年 | 按量付费 |
| Zilliz Cloud | $0.50/月起 | $6/年起 | Milvus云版 |
建议路线:
- 学习/原型:Chroma(免费+简单)
- 生产(国内):Milvus自部署 或 Zilliz Cloud
- 生产(海外):Pinecone
- 已有Postgres:Pgvector
五、手把手搭建RAG知识库实战
接下来我用最简单的Chroma方案,手把手教你搭建一个RAG知识库。整个过程只需要15分钟。
第一步:安装依赖
pip install chromadb langchain openai sentence-transformers第二步:准备文档数据
把你的文档(PDF、TXT、Markdown都行)放到一个文件夹里。这里用3个示例文档演示:
documents = [
"Python是一种高级编程语言,以简洁易读著称。",
"机器学习是人工智能的一个分支,通过数据训练模型。",
"向量数据库用于存储和检索高维向量表示。"
]第三步:创建向量集合
import chromadb
from chromadb.utils import embedding_functions
# 使用sentence-transformers作为embedding模型
embed_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-small-zh-v1.5"
)
client = chromadb.PersistentClient(path="./my_rag_db")
collection = client.get_or_create_collection(
name="knowledge_base",
embedding_function=embed_fn
)
# 插入文档
for i, doc in enumerate(documents):
collection.add(documents=[doc], ids=[f"doc_{i}"])第四步:实现检索问答
def ask_question(question):
# 检索最相关的文档
results = collection.query(
query_texts=[question],
n_results=2
)
# 获取检索到的上下文
context = " ".join(results['documents'][0])
# 用LLM生成回答(这里用伪代码示意)
prompt = f"根据以下信息回答问题:
{context}
问题:{question}"
# answer = call_llm(prompt)
return context, prompt
context, prompt = ask_question("什么是向量数据库?")
print(f"检索到的上下文: {context}")第五步:接入大模型
把检索到的上下文和用户问题一起发给大模型(OpenAI、DeepSeek、本地Ollama都行),就能得到基于你的知识库的回答了。这就是RAG的核心流程:检索 → 拼接Prompt → 生成回答。
想配合Ollama使用本地模型?可以参考Ollama使用教程。
六、常见踩坑与解决方案
踩坑1:维度选错 Embedding模型不同,维度也不同(text-embedding-3-small是1536维,BGE是768维)。建议:一开始就定好模型,别中途换。如果必须换模型,所有已存入的向量都需要重新生成。
踩坑2:索引选错 向量数据库索引主要分 HNSW(精度高、内存大) 和 IVF(压缩、磁盘友好)。百万级用 HNSW,亿级以上用 IVF_PQ 压缩。选错索引会导致查询性能下降10倍以上。
踩坑3:不预处理数据 原始文本直接灌进去,检索效果会很差。必做:清洗 → 分块(chunk_size 500-1000字) → 加元数据(标题/时间/作者) → 再Embedding。
踩坑4:忽略混合检索 纯向量检索经常抓不到关键词。最佳实践:向量检索 + BM25关键词检索 + Reranker重排,效果能提升30%+。Milvus原生支持混合检索。
踩坑5:分块策略不当 文档分块太大(如5000字一块),检索精度低;太小(如100字一块),上下文不完整。推荐:500-1000字一块,相邻块之间设置100-200字的重叠(overlap),确保语义连贯。
踩坑6:忽略元数据过滤 不使用元数据过滤会导致搜索范围过大、结果不精准。建议:在插入向量时附带元数据(文档类型、创建时间、作者、标签等),查询时结合元数据过滤缩小范围。
七、常见问题与解决方案
问题1:向量数据库的数据会丢失吗? 解决方案:Chroma默认存储在本地SQLite中,Milvus用etcd+MinIO做持久化,都有数据备份机制。生产环境建议开启WAL(Write Ahead Log)和定期快照。Pgvector直接复用PostgreSQL的备份机制,最放心。
问题2:Embedding模型怎么选? 解决方案:中文场景推荐BGE系列(BAAI/bge-large-zh-v1.5,1024维),英文场景推荐OpenAI text-embedding-3-small(1536维)。如果追求性价比,可以用Ollama本地跑nomic-embed-text(768维),完全免费。
问题3:向量数据库能存储多少数据? 解决方案:Chroma实测100万条以内稳定运行;Milvus单机版支持千万级,集群版支持十亿级以上;Pinecone理论上无限。建议数据量超过500万条时,从Chroma迁移到Milvus。
问题4:如何评估检索效果? 解决方案:准备一个测试集(100-200条query+标准答案),计算Recall@K和NDCG指标。我的经验是:纯向量检索Recall@10一般在70-80%,加上BM25混合检索能提升到85-90%,再加Reranker能到90-95%。
问题5:向量数据库和Elasticsearch有什么区别? 解决方案:Elasticsearch擅长关键词检索(BM25),向量数据库擅长语义检索。最佳实践是两者结合——用Elasticsearch做关键词过滤,用向量数据库做语义排序。Milvus 2.4+原生支持混合检索,不需要额外部署Elasticsearch。
八、进阶技巧
技巧1:多级检索策略。对于大型知识库,采用”粗筛+精排”策略:先用轻量级索引(如IVF)快速召回Top-100,再用HNSW精确排序取Top-10。这个策略在大数据库上能提升5倍查询速度,精度损失不超过2%。
技巧2:动态分块。不同类型的文档用不同的分块策略:技术文档按章节分块(保留结构信息)、对话记录按轮次分块(保留对话上下文)、代码按函数分块(保留代码完整性)。这种动态策略比固定长度分块效果好20%以上。
技巧3:查询改写。用户的原始查询往往不够精确。在检索前用LLM对查询进行改写(扩展同义词、补充上下文、明确意图),能显著提升检索效果。比如用户搜”怎么做副业”,改写为”AI副业赚钱方法 2026年最新 实操教程”。想了解更多副业方法,可以看看AI副业合集。
技巧4:定期重建索引。当数据量增长超过初始预期的2倍时,建议重建索引。因为HNSW索引在数据分布变化较大时,检索精度会下降。Milvus支持在线重建索引,不影响服务。
技巧5:向量压缩。如果你的向量维度很高(如1536维),可以用PQ(Product Quantization)压缩到原来的1/4-1/8,检索精度损失仅3-5%。这对于降低内存占用和存储成本非常有效。Faiss和Milvus都内置了PQ支持。
技巧6:多模态向量。向量数据库不只能存文本向量。你可以把图片、音频、视频的特征向量也存进去,实现跨模态检索(比如用文字搜索图片)。CLIP模型的图文向量可以直接存入Milvus,实现图文混合搜索。
九、从Chroma迁移到Milvus的实战经验
很多团队在初期用Chroma做原型,数据量增长后需要迁移到Milvus。我分享一次真实的迁移经验。
迁移背景: 一个企业知识库项目,初始阶段用Chroma存储了50万条文档向量,随着业务增长需要扩展到500万条。Chroma在200万条以上时查询延迟明显增加,决定迁移到Milvus。
迁移步骤: 第一步:在目标服务器上部署Milvus(使用Docker Compose,包含Milvus、etcd、MinIO三个组件)。 第二步:编写迁移脚本,从Chroma分批读取向量数据和元数据,写入Milvus。每批1000条,总共500批。 第三步:在Milvus中创建HNSW索引,参数设置为ef_construction=256、M=16。 第四步:用测试集验证迁移后的检索效果,确认Recall@10没有下降。 第五步:切换应用端的连接配置,从Chroma切换到Milvus。
迁移耗时: 数据迁移约2小时,索引用了40分钟,整个切换过程在一个下午完成。
迁移后的改善: 查询延迟从原来的45ms降到3ms(提升15倍),支持并发查询数从5个提升到100个以上,内存占用虽然增加了但完全可控。
迁移注意事项: 一定要先在测试环境完整验证,确认检索效果没有下降再切换生产环境。另外迁移期间保持Chroma可用作为备份,万一出问题可以快速回滚。
想了解更多AI开发实战经验,可以看看AI副业合集中关于技术接单的部分。
十、总结
向量数据库不是越贵越好,关键是匹配你的场景:
- 个人/小项目 → Chroma(5分钟上手)
- 企业/大数据 → Milvus(国产开源,性能最强)
- 不想运维 → Pinecone(海外) / Zilliz Cloud(国内)
- 已有Postgres → Pgvector(零迁移)
- 研究/教学 → Faiss(算法级)
2026年向量数据库已经非常成熟,我的建议是:先用免费版(Chroma/Milvus)把业务跑通,规模化后再切云服务。配合Ollama本地部署和开源Embedding模型,你完全可以在零成本的情况下搭建一个专业级的RAG知识库。
如果你还在纠结,先去免费AI工具大全里找个Chroma练手,边用边学最有效。对于想用Python入门AI开发的朋友,推荐看看Python AI入门指南,里面有更多实战案例。
深度扩展阅读
本文涵盖的内容是AI领域持续发展的方向之一。如果想进一步了解相关知识,可以参考以下推荐阅读: