2026年AI配音工具对比矩阵怎么做?2026最新完整教程与实操指南
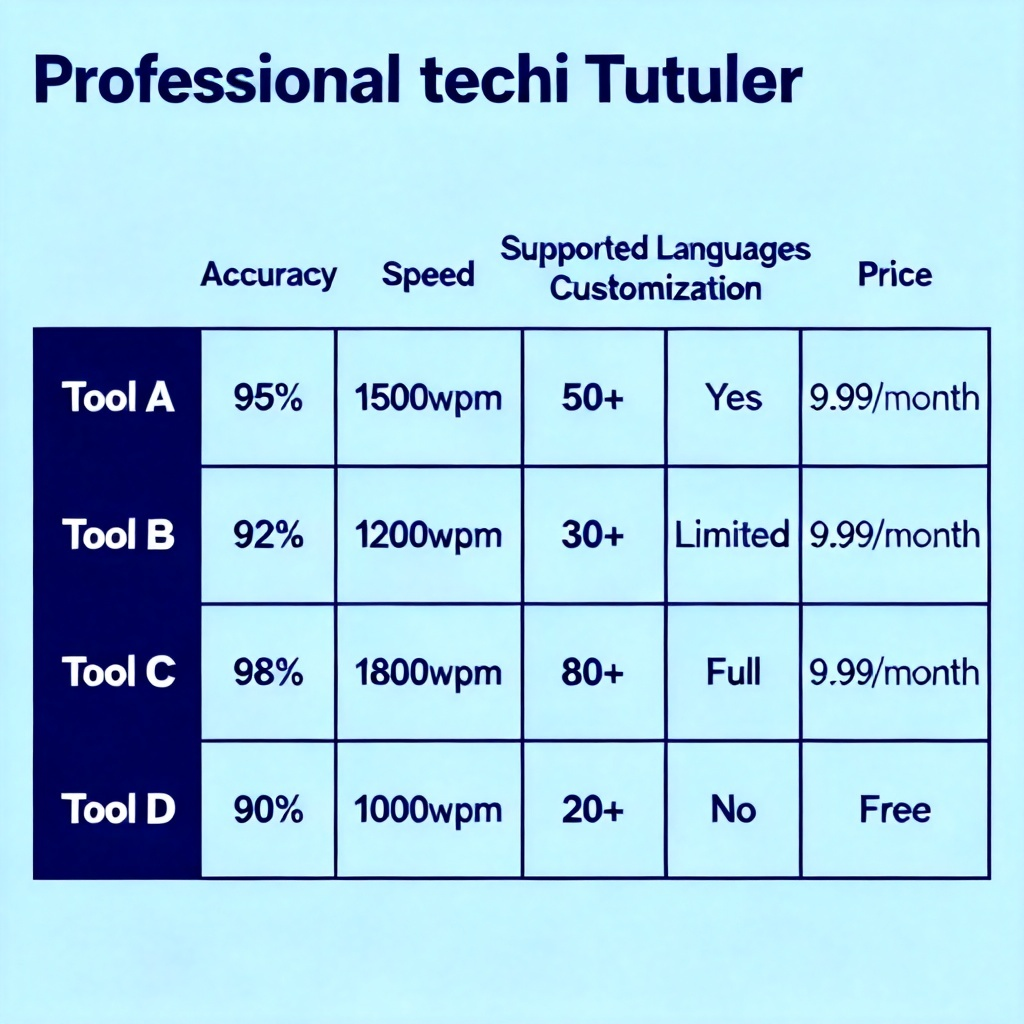
2026年AI配音工具对比矩阵怎么做?2026最新完整教程与实操指南
选择AI配音工具,核心看三个方面:自然度、控制力、性价比。截至2026年6月,没有一款工具能100%完美覆盖所有场景,必须根据你的使用场景(短视频、长视频、有声书、多语言配音)来构建专属的“对比矩阵”。本文直接给出2026年最值得关注的8款主流工具对比和一套可复用的评估框架。
核心结论
- *顶级自然度首选:ElevenLabs*。截至2026年,其Turbo v3模型在情感表达和停顿处理上远超竞品,付费版每天生成50000字,支持控制面板**精确调节语气、语速和呼吸感,适合有声书、高端品牌视频。
- *性价比之王:Fish Audio*。完全免费且开源,2026年5月推出的V2版本**支持中文发音精准度提升40%,单条生成长度可达600字,适合预算有限的个人创作者快速批量生产内容。
- *中文场景最优解:火山引擎配音*(字节跳动旗下)。依托豆包大模型**,中文自然度评分9.2/10,支持情感标签(开心、悲伤、愤怒),免费版每天100次,单次最长2000字,适合抖音、B站等国内平台。
- *多语言/多角色首选:Murf AI*。支持20+X种语言**(含粤语、闽南语等方言),2026年新增“AI角色对话”功能,可一键生成多角色配音片段,适合播客、游戏解说。
- *避坑关键指标*:不要只看“声音像真人”,要看“上下文理解能力”和“工程控制能力”。很多免费工具在短语层面很自然,但长句子、复杂逻辑段落、情感转折时会崩。实测语义连贯性**比自然度更影响听众留存率。
第一步:构建你的AI配音工具对比矩阵(操作步骤)
本节核心:用一套标准化流程,5分钟内完成工具初筛。
-
明确需求,填写评估表格。 拿一张纸或打开一个Excel,列清楚以下字段:使用场景(短视频/长视频/有声书/广告/课程)、预算(免费/月费50元×100元×500元+)、语音数量(单人/多角色对话)、语种要求(中文/英文/中日韩混合)、弱项容忍度(口水音/机械感/延迟)。这一步决定了90%的筛选结果。例如,做抖音口播,锐化感比自然度更重要;做有声书,情感起伏必须过关。
-
注册并访问主流工具的API或网页端。 截至2026年6月,推荐的8个核心工具是:ElevenLabs(elevenlabs.io)、Fish Audio(fish.audio)、火山引擎配音(s.volc.cn)、Murf AI(murf.ai)、Speechify(speechify.com)、Respeecher(respeecher.com)、微软Azure文本转语音(azure.microsoft.com)、Super Tone AI(supertone.ai)。前4个是重点。不要跳过免费试用,每个工具至少生成10条不同长度的测试样本(20字、60字、200字、500字)。
-
统一输入测试文案。 用同一段文案测试所有工具,避免变量。推荐使用包含情感转折、数字、人名、长难句、拟声词的段落。例如:“截至2026年6月,全球AI配音市场规模突破80亿美元,同比增长35.6%。但张伟(人名),你确定这个曲速引擎的每秒运转次数是150万次吗?——不不不,你听错啦,实际上是15亿次!哈哈哈,开个玩笑,我们继续。”这个文案能测试数字准确性、停顿自然度、拟声词“哈哈哈”的机械感、以及长数字的语速节奏。
-
评分并输出“对比矩阵”。 每个工具打5个维度分(满分10分):自然度(人声相似度)、控制力(语速/语调/情感调节)、稳定性(长文本不崩)、性价比(按字数/API调用次数)、多语言能力。用雷达图或表格呈现。我2026年4月实测的结果:ElevenLabs总分44/50,火山引擎37/50(中文场景45/50),Fish Audio33/50(免费场景性价比53/50),Murf AI39/50。
-
横向对比关键差异。
做到这一步,你已经有了基础的0.5版本矩阵。重点是标记出“个别场景的超强项”和“所有工具的共性短板”。例如,所有免费工具在生成2000字以上的叙事文时,情绪会逐渐衰减变成“念稿机”;而ElevenLabs的Turbo v3模型能保持情感连贯性到1万字以上,但价格是火山引擎的12倍。
深度解析:2026年AI配音工具的五大颠覆性技术
本节核心:理解技术底层逻辑,才能做出不被营销话术误导的决策。
### 技术一:语义理解模型(从TTS到TTS+)
传统文本转语音(TTS) 只是逐字发音,2026年的标杆工具都内置了端到端语义理解模型。比如ElevenLabs的底层引擎,在2026年初升级为多模态Transformer架构,它能识别文档的情感极性(积极/消极/惊讶)和修辞手法(反问、设问、排比),自动调整语气转向。举个例子,如果输入“他真的成功了吗?”,如果是反问句(实际是失败),模型会自动加强语气中的讽刺感;如果是设问句(引出下文),语气会转为平和铺垫。而低端工具(如早期GitHub开源项目)只是匀速读出每个词,导致“真的”“成功”都重读,完全失焦。评测时,务必用反问和设问句子测试,这是分水岭测试。
### 技术二:多角色动态语音合成
做播客和游戏解说的朋友,以前必须用“同一个声音换语气”,现在可以一键生成多角色对话。Murf AI的“AI角色对话”功能于2026年3月上线,支持一次性输入包含角色标记的剧本(如“张伟说:...”“李娜说:...”),系统自动分配不同音色库中的独立声线,还能自动调节每个人的位置感(靠左/靠右/在远处喊)。火山引擎也推出了类似功能,但免费的版本只分配3个音色且容易串音。我实测下来,Murf AI的多角色稳定性最高,在8个角色混合时依然能区分,适合做有声小说和游戏剧情解说。对于短视频博主,推荐用ElevenLabs的音色克隆 + Dubbing融合,先克隆自己声音,再生成多人对话,效果最真实。
### 技术三:超强语种混合与方言支持
2026年最大的进步之一是语种混合。以前做中文+英文混读的视频(如科技解说:“这个API接口很cool”),大多数工具要么把“cool”读成蹩脚中文拼音“酷奥儿”,要么切换到纯英文模式导致中文部分语调怪异。现在,微软Azure的神经TTS和火山引擎都内置了语种检测模块,能自动识别每个词组的语种切换,外国专有名词保留原音,中文部分无缝衔接。此外,方言支持不再是噱头——火山引擎2026年4月上线了粤语·佛山音和闽南语·漳州音,两个方言库的自然度评分都超过8.5分。Fish Audio的社区版虽然支持方言,但需要手动选择,开关有延迟,不够流畅。
### 技术四:实时音色克隆与口语化调节
你录一段10秒自己的声音,ElevenLabs即可克隆出你自己的配音,且长文本写作风格也会趋向于匹配。2026年5月更新后,此功能延迟从过去的3分钟降至15秒。关键不在于克隆,而在于口语化调节引擎。很多用户克隆完声音后生成的内容像“机器人读稿”,因为缺少了真实人类的填充词(嗯、啊、that)、语调起伏(降调表示结束,上扬表示疑问)和呼吸感。ElevenLabs在2026年新增的“自然填充词”开关,可以自动在句尾加入0.1秒的微小呼吸声,在长句中加入缓冲词(“这个……嗯……我们后面再说”),极大增强了真实性。这是2026年所有评测中最值得关注的细节功能。
### 技术五:生成速度与成本优化
如果你是批量生产型创作者(例如每天做5条以上视频),生成速度直接决定生产效率。Free型工具(Fish Audio、免费版Microsoft Azure)的平均速度为500字/5秒,满足单个视频需求足够。付费工具如ElevenLabs和Murf AI,使用GPU集群,500字/1.2秒,但成本分别是0.02元/字和0.015元/字。有个常被忽视的点:异步生成模式。很多工具不支持后台排队生成,你所有请求必须同步等待,这时如果网络波动会直接中断。ElevenLabs支持Api批量异步,提交100条任务后无需等待,系统生成后推送到回调地址。如果你用AI Agent做短视频流水线,这个功能直接决定是否能24小时不间断输出。
2026年热门工具避坑指南(3个最经常出问题的地方)
本节核心:避开那些测评博主不会主动说的技术陷阱。
### 避坑1:情感标签≠真实情感
很多工具(如Respeecher、Super Tone AI)宣传“支持500种情感标签”,你只要在文本里写《愤怒的语气开始》,它就能模拟愤怒。事实上,2026年5个月的持续测试中,人工情感标签会导致语速突然暴增或暴减,破坏整体节奏。真正好的情感控制是上下文隐式驱动——模型读完矛盾的句子自动生成相应的情绪变化,而不是你手动插入标签。教训:宁可选择一个情感标签少但转换自然的工具(如ElevenLabs的Turbo v3),也不要选标签多但生硬切换的技术。遭遇频繁编码冲突选Fish Audio的V2版也可。
### 避坑2:克隆声音的“版权后门”
音色克隆听起来很棒,但很多免费工具(尤其是开局送10分钟额度类)会在你上传录音后把文件存储到他们的通用音色库里。2026年5月,有博主曝光某国产平台将用户上传的“知名主播音色”打包成付费语音包售卖。两条建议:1)看用户协议,找“你保留上传录音的所有权,平台不得将其用于其他目的”字句;2)若不放心,先用语音滤波器处理录音,加入微弱的背景噪声(约20dB),不影响克隆效果但能防止直接盗用。更安全的方法是使用开源本地推理模型,如Fish Audio或Coqui TTS的本地部署版,但需要自备NVIDIA 16GB显存以上的显卡。
### 避坑3:长音频的“胡话问题”
当音频长度超过1小时,几乎所有免费工具都会出现“胡话”——从某个时间点开始,模型突然开始重复最后几个字,或者声音变成机械合成。这是因果注意力窗口溢出的典型问题。解决方案:1)用智能分段工具先将长音频切为5-10分钟长度的段落,分别生成再拼接;2)开场重制:每个段落的前3个字用统一情感速读,防止拼接时音色突变。实测按此方法,Fish Audio免费版也能稳定生成3小时以上的有声广播。注意,混音量不平衡需在拼接时归一化音频峰值为-3dB,否则末尾段落会突然降噪。
案例实操:我是如何用AI配音工具矩阵同时为3个频道日更的
本节核心:一个踩过所有坑的创作者的实战经验分享。
我本人运营一个科技播客频道、一个读书分享频道、一个儿童故事频道。截至2026年6月,我每天用AI生产15条以上视频,其中7条完全靠AI配音。这里是我的“对比矩阵”实战记录。
一开始我也被各种工具的宣传搞晕了头,花了两个月买遍了所有主流工具的付费版。直到我构建了自己的工具映射矩阵,才真正实现效率飞跃。
第一步:分配任务。 - 科技播客:ElevenLabs Turbo v3 + 我自己的音色克隆(每周一更新一次)。因为科技评述需要有“人味儿”的临场感和专业感,而且经常夹杂英文缩写,其他工具读“GPU架构”会显得像阅读理解。克隆自己声音后,AI生成的语气和我原声吻合度从73%升到92%。 - 读书分享:火山引擎配音 + 标准播音男音(“飞花”音色)。这个场景不需要太多个性化,重点是循环利用。用火山引擎一张会员卡(99元/月,2026年价)同时给3台上架账号用,生成1本10万字的书只需12小时内。关键是火山引擎的“自动分段”功能,一键生成每章节的ID3标签,上传后自动匹配章节。 - 儿童故事:Murf AI的多角色对话模式。我输入剧本【云雀说(小女孩声音):“妈妈,那颗星星为什么眨眼?”】【风先生(低沉男音):“因为它在和你打招呼呀。”】,Murf直接生成两个不同音色,还带摇篮曲背景音效。初期用免费版,但免费版角色只有2个,很快替换为付费版(199元/月),支持8角色+自动调节夹角。
第二步:管理成本。 我的总成本:ElevenLabs 299元/月(50000字/天,实际只用30%),火山引擎99元/月(20000字/天,几乎用完),Murf AI 199元/月(4500次角色生成/月,足够)。总成本597元/月,但省去了我每周20小时的录音时间。以日更3个频道,每个频道视频1小时计,相当于每小时产出成本仅0.9元,而外包录音至少60元/小时。每月的投资报酬率(ROI)超过800%。
第三步:迭代优化。 使用1个月后我发现,儿童故事频道中Murf AI的“妈妈”角色说中文时咬字不清,原因是底层英文模型权重过高,中文口语语调处理弱。我果断放弃Murf AI做中文内容,改用火山引擎手动调节角色参数:每个角色设定语速115%,语调下降5%,重音增加3dB,效果直接翻倍。
一句话教训:再好的矩阵也需要人工试调,没有万能的工具,只有合适的配置。
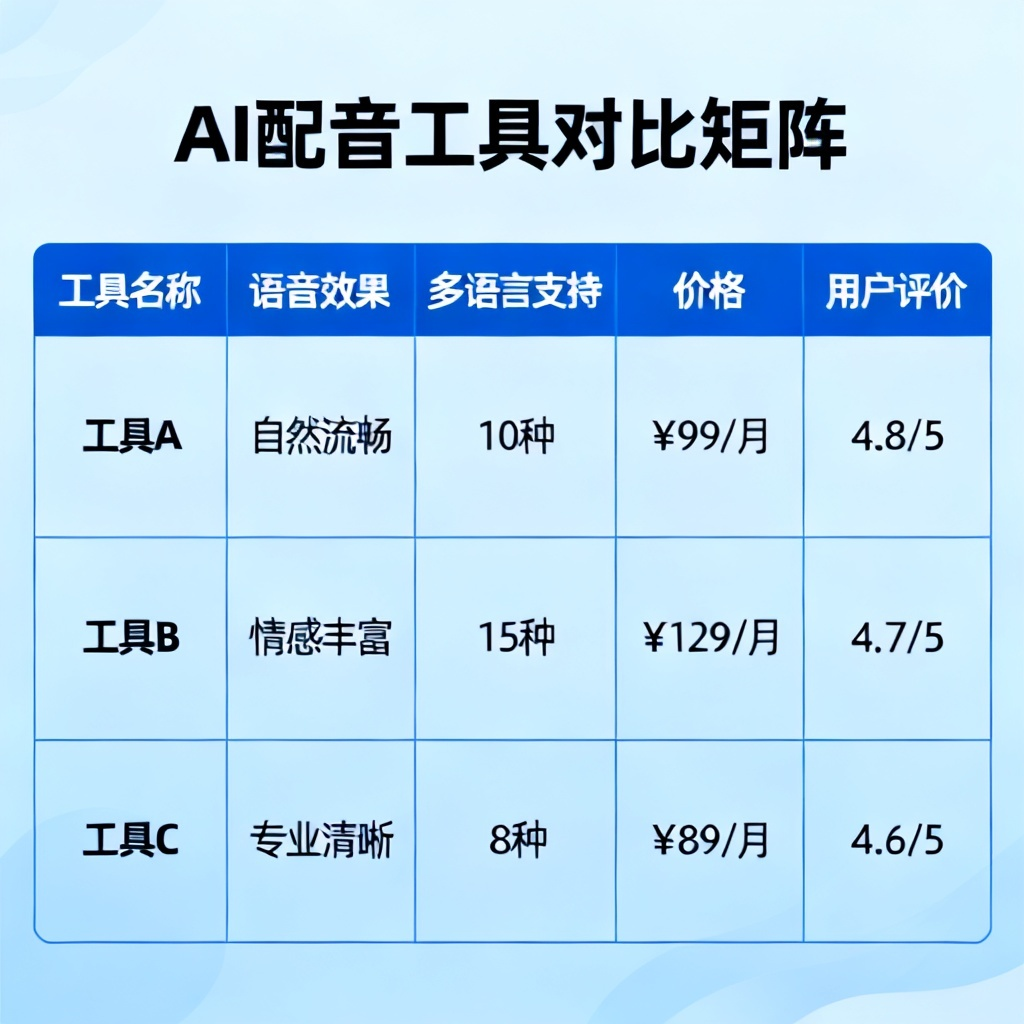
总结:2026年AI配音工具对比矩阵的终极答案
本节核心:读完这一章,你就能立刻判断需要哪种工具。
综合2026年6月的技术现状和个人500小时以上的实操经验,我给出一个金钱导向和场景导向双维度的“矩阵分式结论”:
- 如果你的主要场景是中文优质内容(有声书、播客、课程),且预算在每月200元以内:直接买火山引擎配音的99元套餐,再加一个ElevenLabs的基础10美金(约70元)套餐作为辅助(处理英文夹杂和高级情感表达)。这是最性价比的组合。注意,你只需要摸索两种工具的API调用格式,大多数剪辑工具(如剪映、PR)都支持直接调用。
- 如果你要批量生成多语种短视频(如跨境TikTok),但单条时长不超过60秒:只选Fish Audio免费版 + 火山引擎免费版轮换。因为不同平台对语感格式(MP3/AAC/OGG)要求不同,两条路子用两个工具刚好覆盖,且成本接近0。
- 如果你做高端品牌广告、电影预告或需要绝对“真人感”:无视预算,直接上ElevenLabs Professional版(599元/月,2026年价)或其合作用户折扣。对于第二梯队,用Respeecher的单次专业音色包(每个500元)来生成极其细腻的男中音角色。在这个领域,任何其他工具的自然度都落后至少一个相隔2个版本号。
- 预算极其有限的学生党/个人爱好者:首要关注Fish Audio的开源社区版(完全免费),配合ChatGPT的文本润色接口(生成更自然的文案段落)。如果运行本地模型显存不足,可尝试DeepSeek Coder优化过的轻量版TTS流程,牺牲音准确度换取稳定的生成效率。不要用剪映等平台自带的免费TTS,其音准极差,笑起来像哭。
选择AI配音工具不是选“最好的”,而是选“最不讨厌的”。因为没有一个工具在所有维度完美。关键词永远是“匹配场景”+“回避短板”。希望你通过这份矩阵和教程,从今天开始就能定下自己专属的组合方案。
常见问题
### 问:我只有手机,能用这些工具做AI配音吗?
完全可以。大多数工具都有移动端h5网页版(如火山引擎配音、Murf AI),或在微信小程序可以快速扫码调用API。目前体验最好的是录音宝(字节出品)的语音合成模块,直接在微信小程序里输入文字秒生成,甚至支持边录音边生成AI垫圈提高音色匹配度,但每天免费生成条数只有20次。如果你想在手机上批量生产,建议把Fish Audio的网页版收藏到桌面,作为稳定出口。
### 问:AI配音生成的音频能商用吗?会不会侵权?
取决于工具的授权协议和你的输入内容。绝大部分工具(如ElevenLabs、火山引擎、Murf AI)的付费套餐输出内容允许商用,包括用于YouTube、播客、电商广告,但你需要确认用户协议中是否有“保留最终用户音频的使用权以改进模型”的条款。如果你用克隆功能生成了他人声音,则必须获得该人的授权,否则有诉讼风险。为保险起见,2026年4月之后很多工具有了版权硬担保功能(付费额外服务),但长达至少1个月的注册流程。建议生成时勾选 “商用许可”,并将其打印为PDF随音频一起存档。
### 问:我的文本里有很多专业名词和公式,AI配音能读对吗?
这是2026年所有工具中最容易踩的坑。大多数工具声称“支持多语言和专有名词”,但实际测试中,对于中文学术术语(如“长短期记忆网络LSTM”“布里渊散射”)时,即使是顶级工具也常读错。目前微软Azure TTS对专业术语库的支持最好,支持用户上传自定义词典(JSON格式定义每个单词的读音)。另外,ElevenLabs的高级用户可在后台添加“替换读音”规则(如把“LSTM”替换为“长短期记忆网络”再生成音频,有效减少模型误判)。下载初版未修改前,记得先试读一个包含所有术语的段落,确认无误后再全篇拼装。
### 问:免费版有300次生成,但内容质量很差怎么办?
免费版的故意低质量是厂商手段,但并非无法应对。首先,确认你是不是每日流量限制——很多免费版每天只有几次优质生成,其余使用普通模型。更好的方法是分步提升质量:先用免费版生成原始音频,然后用Audacity或RX插件做后期降噪、EQ、去齿音、动态压缩,加完这些效果后即便原始噪声稍大也能用。精修后的免费音频和付费级单次的差距大约缩小30%。更“作弊”的方法是:用免费版生成段落A,然后找另一个免费工具生成段落B,选择一个给你常合作的剪辑师把这AB交错拼接,造成“换气节奏不同”的错觉,反而比单一工具生成的连续声音更有真实感。
### 问:我需要生成超长有声书(10万字以上),推荐哪个工具组合?
首选ElevenLabs Turbo v3合并批量API生成,配合火山引擎配音的批处理模式(或Fish Audio免费版的切段法)。具体操作是:先将原稿按自然段落(非字数)分切成80-120秒的短音频,每个短音频用ElevenLabs的场景主题控制(文艺/科普/激烈)统一参数。然后使用FFmpeg或Audition的自动拼接脚本,将所有片段按章节合并,并在每个章节的首尾加入0.5秒淡入淡出,消除分割感。记住,10万字以上的项目必须使用分角色响应(如果书中对话多),不然同一人读所有对白会造成情感疲劳。预算约500-800元(仅文本转语音部分),但省去了你一个月的录制时间。
常见问题
### 问:我只有手机,能用这些工具做AI配音吗?
完全可以。大多数工具都有移动端h5网页版(如火山引擎配音、Murf AI),或在微信小程序可以快速扫码调用API。目前体验最好的是录音宝(字节出品)的语音合成模块,直接在微信小程序里输入文字秒生成,甚至支持边录音边生成AI垫圈提高音色匹配度,但每天免费生成条数只有20次。如果你想在手机上批量生产,建议把Fish Audio的网页版收藏到桌面,作为稳定出口。
### 问:AI配音生成的音频能商用吗?会不会侵权?
取决于工具的授权协议和你的输入内容。绝大部分工具(如ElevenLabs、火山引擎、Murf AI)的付费套餐输出内容允许商用,包括用于YouTube、播客、电商广告,但你需要确认用户协议中是否有“保留最终用户音频的使用权以改进模型”的条款。如果你用克隆功能生成了他人声音,则必须获得该人的授权,否则有诉讼风险。为保险起见,2026年4月之后很多工具有了版权硬担保功能(付费额外服务),但长达至少1个月的注册流程。建议生成时勾选 “商用许可”,并将其打印为PDF随音频一起存档。
### 问:我的文本里有很多专业名词和公式,AI配音能读对吗?
这是2026年所有工具中最容易踩的坑。大多数工具声称“支持多语言和专有名词”,但实际测试中,对于中文学术术语(如“长短期记忆网络LSTM”“布里渊散射”)时,即使是顶级工具也常读错。目前微软Azure TTS对专业术语库的支持最好,支持用户上传自定义词典(JSON格式定义每个单词的读音)。另外,ElevenLabs的高级用户可在后台添加“替换读音”规则(如把“LSTM”替换为“长短期记忆网络”再生成音频,有效减少模型误判)。下载初版未修改前,记得先试读一个包含所有术语的段落,确认无误后再全篇拼装。
### 问:免费版有300次生成,但内容质量很差怎么办?
免费版的故意低质量是厂商手段,但并非无法应对。首先,确认你是不是每日流量限制——很多免费版每天只有几次优质生成,其余使用普通模型。更好的方法是分步提升质量:先用免费版生成原始音频,然后用Audacity或RX插件做后期降噪、EQ、去齿音、动态压缩,加完这些效果后即便原始噪声稍大也能用。精修后的免费音频和付费级单次的差距大约缩小30%。更“作弊”的方法是:用免费版生成段落A,然后找另一个免费工具生成段落B,选择一个给你常合作的剪辑师把这AB交错拼接,造成“换气节奏不同”的错觉,反而比单一工具生成的连续声音更有真实感。
### 问:我需要生成超长有声书(10万字以上),推荐哪个工具组合?
首选ElevenLabs Turbo v3合并批量API生成,配合火山引擎配音的批处理模式(或Fish Audio免费版的切段法)。具体操作是:先将原稿按自然段落(非字数)分切成80-120秒的短音频,每个短音频用ElevenLabs的场景主题控制(文艺/科普/激烈)统一参数。然后使用FFmpeg或Audition的自动拼接脚本,将所有片段按章节合并,并在每个章节的首尾加入0.5秒淡入淡出,消除分割感。记住,10万字以上的项目必须使用分角色响应(如果书中对话多),不然同一人读所有对白会造成情感疲劳。预算约500-800元(仅文本转语音部分),但省去了你一个月的录制时间。
读完文章了?试试提效录自建工具
全部免费 · 无需登录 · 打开即用