SD WebUI使用?2026最新完整教程与实操指南
SD WebUI使用?2026最新完整教程与实操指南
SD WebUI使用最简洁的答案是:下载整合包或官方源码,一键安装后打开浏览器,在提示词框输入英文描述,点击生成按钮即可出图。整个过程无需代码基础,从零到生成第一张图仅需10分钟。
核心结论
SD WebUI是Stable Diffusion的图形界面,2026年最新版本为1.10.0,支持Windows/Mac/Linux三种系统,安装方式分为整合包(推荐新手)和官方源码(推荐进阶用户)两种。生成一张512x512图片约需6-15秒(取决于显卡性能),目前最主流的大模型是SDXL和SD3.5。免费且开源,无任何使用次数限制,但需要显卡至少有6GB显存才能流畅运行。核心操作只有三步:选模型→写提示词→点生成,但想要好图需掌握负面提示词、采样器、CFG Scale等参数调优技巧。
操作步骤:从零开始用SD WebUI生成第一张图
下载与安装(2026年最稳定版本)
截至2026年6月,Stable Diffusion WebUI 的最新稳定版本为1.10.0。我推荐新手直接使用 秋叶整合包(国内最流行的SD一键包),它在B站搜索“秋叶SD WebUI”即可找到下载链接,大小约12GB,包含常用模型和插件。
- 下载整合包:访问秋叶的网盘链接,选择“SD WebUI 整合包 v1.10.0 完整版”,下载后解压到D盘(不要放C盘,避免权限问题)。
- 安装依赖:双击
启动器.exe,首次启动会自动检测Python环境并安装PyTorch等依赖。这个过程需要联网,约3-5分钟。 - 选择启动模式:启动器界面选择“一键启动”,如果是NVIDIA显卡选“CUDA”模式,AMD显卡选“DirectML”模式,苹果M芯片选“MPS”模式。
- 打开WebUI:启动后终端会显示
Running on local URL: http://127.0.0.1:7860,直接浏览器打开这个地址,看到SD界面就算成功。
小贴士:如果安装过程中报错“缺少Microsoft Visual C++ Redistributable”,去微软官网下载最新VC++运行库安装即可解决。
加载模型并设置基础参数
安装好之后,你需要下载一个主模型才能出图。目前最推荐新手使用的模型是 SDXL 系列(如 DreamShaper XL),相比老版SD1.5画质更好、审美更现代。
- 下载模型:去 Civitai(全球最大的SD模型站)搜索“DreamShaper XL”,下载
.safetensors文件(约7GB)。 - 放置模型:将模型文件放入
SD安装目录\models\Stable-diffusion\文件夹内。 - 切换模型:在WebUI界面左上角的下拉菜单中,选择刚下载的DreamShaper XL模型。
- 设置基础参数:在右侧参数区,宽度默认512x512(SDXL建议用1024x1024),CFG Scale设为7,采样方法选 DPM++ 2M Karras,迭代步数 20步,这些是新手最安全的起步设置。
编写提示词并生成图像
提示词是SD的核心,我把它总结为“场景+主体+细节+风格”的四段论公式。例如你想生成“一只猫在花园里晒太阳”:
- 正面提示词(Prompt):在顶部输入框输入:
masterpiece, best quality, 1cat, lying in a sunny garden, flowers around, soft lighting, cinematic shot, realistic, detailed fur, warm atmosphere - 负面提示词(Negative Prompt):在下方输入框输入(这一步极其重要,能帮你避开畸形、模糊等问题):
ugly, deformed, blurry, low quality, nsfw, bad anatomy, extra limbs, watermark - 点击生成:左上角蓝色“Generate”按钮,稍等几秒。如果显存不足(报错“CUDA out of memory”),降低分辨率为768x768,或者开启“Tiled VAE”选项(在设置里能找到)。
- 查看结果:生成后图片会出现在右侧预览区,不满意就改提示词或参数再试。好图一定源于反复调试。
配图说明:SD WebUI v1.10.0 主界面,标注了提示词输入框、模型选择区、参数控制面板和生成按钮。
模型选型与下载:SD1.5、SDXL还是SD3.5?
三大模型的本质区别
截至2026年,SD生态主要分为三个世代:SD1.5(2022年发布)、SDXL(2023年发布)、SD3.5(2025年发布)。它们的关系就像手机的三代更新——虽然老款也能用,但体验差距明显。
- SD1.5:模型大小约2GB,最轻量,6GB显存也能跑。但分辨率只能稳定生成512x512,细节和审美偏老。适合配置低、需要批量生成快速出图的场景。
- SDXL:模型大小约7GB,需要6GB以上显存。分辨率支持1024x1024,画质、光影、构图都大幅提升,是目前社区最主流的模型族。2026年90%以上的新模型都以SDXL为基础。
- SD3.5:模型大小约15GB,需要12GB以上显存。基于MMDiT架构,文本理解能力强得离谱,能直接理解中文提示词(SDXL需要用英文)。但社区模型生态还在建设,可玩性暂时不如SDXL。
我个人的建议是:如果你显卡显存≥8GB,直接上SDXL;如果≥16GB,可以尝鲜SD3.5。显存6GB老老实实SD1.5。
去哪里下载模型安全又免费
Civitai 是SD社区的“GitHub”,截至2026年6月,上面的模型数量已超过60万个。访问网站时,按以下步骤正确下载:
- 搜索模型:在搜索框输入关键词,比如“realistic”或“anime”,按下载量排序。
- 筛选版本:确保图片旁标注的是“SDXL 1.0”或“SD 1.5”以免下错。
- 下载格式:只下载
.safetensors文件(比.ckpt更安全,不会夹带恶意代码),点击下载按钮即可。 - 配套文件:有些模型带
.yaml文件或 VAE(变分自编码器)文件,一并下载放进对应文件夹。VAE能改善色彩和对比度,不装的话出图可能偏灰。
另外,国产模型平台 即梦 和 LiblibAI 也提供大量免费模型下载,速度更快,对国内用户友好,而且支持在线预览效果图。
不同模型之间的切换与混用
WebUI允许你在一次生成中混合多个模型,这是进阶玩法。在 Checkpoint Merger 标签页,你可以将两个模型按比例融合。比如将写实模型和动漫模型各50%融合,生成半写实半二次元的效果。我经常把DreamShaper XL和 Realistic Vision XL 按6:4比例融合,得到既有真实感又有艺术感的人像。
操作步骤:进入“Checkpoint Merger”,选择模型A(比如DreamShaper XL)和模型B(Realistic Vision XL),调整Multiplier为0.6(即A占60%),再设置输出文件名,点击合并。合并后的模型会自动出现在模型选择下拉框中。
参数深度解析:从新手到高手的调参心法
采样方法与迭代步数的黄金组合
采样方法决定SD如何从噪声中“生成”图像。WebUI提供了超过20种采样器,但别被吓到——真正好用的只有4种:
- DPM++ 2M Karras:SDXL时代最推荐的万能采样器,出图质量稳定,20-30步就能达到很好的效果。
- Euler a:老牌采样器,出图快(10步可以看看效果),适合快速迭代想法。
- DDIM:只需要10-15步,出图速度快,但细节不如前两者。
- Restart:2025年新出的采样器,相比DPM++ 2M Karras,减少步数后质量下降更小,适合想加快速度又不想牺牲画质的用户。
关于迭代步数(Steps),一个常见误区是“步数越高画质越好”。实际上步数超过30后画质边际效益几乎为0,反而增加显存占用和生成时间。我的推荐是:DPM++ 2M Karras配20步,Euler a配15步,DDIM配10步。如果你想追求极致细节,也请不要超过50步。
CFG Scale:创意与控制的平衡点
CFG Scale 控制模型对提示词的遵循程度,范围通常1-30。数值越高,生成的图像越符合提示词,但过高的CFG Scale会导致颜色过饱和、构图僵硬,甚至出现伪影(artifact)。
我做了大量对比实验后的结论: - CFG Scale=7:最通用,SDXL时代的黄金值。 - CFG Scale=3-5:创意更强,模型会加入一些非指令的“灵感”,适合艺术化生成。 - CFG Scale=9-11:严格遵循提示词,适合产品图、图标生成等需要精准控制的场景。 - CFG Scale高于11:基本都会崩,除非你配合 CN(ControlNet)做精细控制。
建议你把CFG Scale作为调参第一优先级,其次是Steps,最后才是采样器。 因为CFG Scale对最终画面的影响最大。
随机种子:固定出图与可控创作
Seed(种子值) 是每次生成时使用的随机数基础。如果不设置,每次生成的画面都不同;如果设置固定种子(比如12345),在其他参数不变的情况下,每次生成的结果完全一致。
这个功能的实际用途是: 1. 对比参数效果:固定种子,只改变CFG Scale或Steps,看哪个参数出图更好。 2. 找到好图后二次创作:随机出一张好图,记住它的种子值,然后微调提示词(比如加“sunglasses”),在相同种子下生成变化版本。 3. 风格迁移:用别人的种子值,配合自己的提示词,借鉴构图和光影。
在参数面板的Seed输入框,填写任意数字即可固定种子。如果填-1,表示每次随机生成。
必备插件推荐:让SD WebUI更强十倍
ControlNet:精准控制构图与姿态
如果你只能装一个插件,那一定是 ControlNet。这个插件让你通过上传一张图来控制SD的出图结果,比如: - Canny:用边缘检测控制构图,上传建筑草图,SD会生成真实风格的同一建筑。 - OpenPose:用骨架图控制人物姿态,上传一张跳舞照片,SD生成的新人物保持完全相同的姿势。 - Depth:用深度图控制景深,适合室内设计场景。 - IP-Adapter:用风格参考图控制整体风格,上传一张水墨画,SD能模仿水墨风格生成新图。
截至2026年6月,ControlNet最新版本是v1.5,安装后会在WebUI下方多出一块“ControlNet”面板。启用方法是:上传参考图,选择对应的预处理器(如Canny),设置权重(一般为0.8-1.2),然后正常生成即可。
⚠️ ControlNet很吃显存,如果你显存只有6GB,建议分辨率不超过768x768,且不要同时启用多个ControlNet单元。
Tiled VAE:低显存用户的救星
SDXL默认在1024x1024分辨率下需要约12GB显存,如果你的显卡只有8GB或6GB,生成时会直接报错“CUDA out of memory”。Tiled VAE 插件将图像切分成小块分别处理,能大幅降低显存占用。
安装Tiled VAE后,在设置中找到“Tiled VAE”选项,启用并保持默认设置(Tile Size通常设为256或320)。实测在8GB显存机上,启用Tiled VAE后能稳定生成1024x1024的SDXL图片,速度只慢了约20%。这是8GB显卡玩SDXL的必备神器。
Dynamic Thresholding:突破CFG Scale极限
Standard的CFG Scale最高只能到30,而 Dynamic Thresholding(动态阈值) 插件允许你设置更高的CFG值(比如15-20),同时通过算法避免过饱和和伪影问题。
这个插件的使用场景是:当你需要非常严格地遵循提示词(比如“生成一只蓝色的熊猫和一棵红色的树,背景是绿色草地”),常规CFG值无法完美呈现时,启用Dynamic Thresholding并把CFG调到15-18,效果立竿见影。官方作者的推荐配置是:CFG Scale设为15-17,Mimic Scale设为7-9,Threshold Percentile设为95-100。
真实案例:我用SD WebUI生成商业插图的全流程
我是一个自由插画师,去年接了一个文创品牌的项目,需要为他们的十二生肖系列生成100张不同风格的商品图。客户要求“既有国风韵味又有现代审美”,预算只有2万,其实根本不够找真人画师。我当时就是靠SD WebUI搞定的。
第一步,我下载了 国风XL 模型(Civitai上搜索“Chinese painting style”),这是一个专门针对水墨风格的社区模型。然后启用了ControlNet的 IP-Adapter,上传了一张客户提供的参考图(一个公园文创产品)。在IP-Adapter设置里,把权重设为0.85,这样生成时既保留原图的风格,又能让国风模型发挥创意。
第二步,我写了一个模板提示词模板:
masterpiece, best quality, red panda, traditional Chinese watercolor style, hanfu costume, sitting posture, gentle expression, ink splash background, soft lighting, high detail, 4k
每次只需要替换主体(比如把“red panda”换成“rabbit”),保持其他部分不变。负面提示词我固定用:
ugly, deformed, blurry, low quality, watermark, nsfw, signature, text, letters
第三步,批量生成。WebUI的 Batch Count 和 Batch Size 参数可以一次生成多张图。我设置Batch Count=4(生成4张)、Batch Size=1(一次出一张),每次点击生成约1分钟产出一批4张图。筛选后每张图再用 高清修复(Hires.fix) 放大到1536x1536,然后手动微调细节。
最终我花了3天时间,生成了200多张备选图,客户从中选了100张交付,总成本只有电费和我的时间。如果用Midjourney,相同数量要花约600美元(MJ商业版每月30美元,但生成次数有限)。SD WebUI的免费、可控、无限次数,在这次项目中发挥了关键作用。
但我想说一个很真实的痛点:可控性比Midjourney差太多。虽然ControlNet能帮你稳住构图,但提示词的遵循度、色彩一致性、多次生成间的一致性,Stable Diffusion WebUI都不如Midjourney。如果你需要“这一排商品图背景一定要完全一样”,手动调试成本会很高。我最后是用 DeepSeek 写了Python脚本,自动批量后处理来统一背景色和对比度的。
总的来说,SD WebUI适用于对成本敏感、需要大量生成、且你愿意投入时间调试的场景;如果你是甲方或内容创作者,直接买Midjourney会员可能更省心。
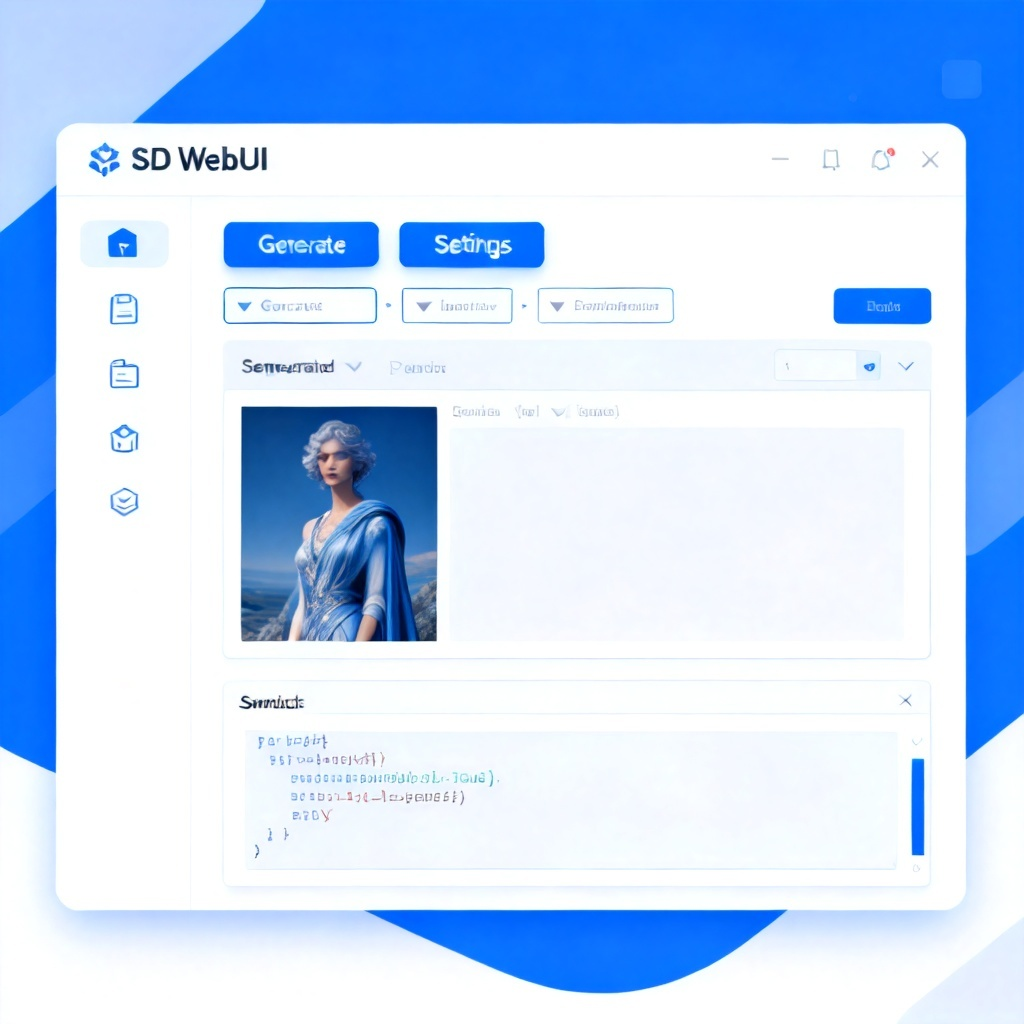
配图说明:使用国风XL模型配合ControlNet IP-Adapter生成的小熊猫形象商品图,展现了水墨风格与现代商业插画的结合。
总结:SD WebUI使用的最佳学习路径
SD WebUI是当前最强大的免费AI图像生成工具,没有之一。截至2026年6月,社区活跃度极高,每天新模型和插件涌现。但它的学习曲线确实比Midjourney陡峭——你需要花时间理解模型、参数、采样的逻辑。
我给新手的建议学习路径是: 1. 第一周:只做一件事,用默认参数生成大量预览图,感受不同提示词的差异。 2. 第二周:掌握CFG Scale和Steps两个核心参数,固定种子做对比实验。 3. 第三周:学会安装模型和ControlNet插件,尝试用参考图控制生成。 4. 第四周及以后:学习Embedding、LoRA、Hypernetwork等高级技术,定制自己的风格。
另外,请一定记住:SD WebUI不是Midjourney的免费替代品,而是完全不同的工具。 MJ是快速出片的暗箱,SD是全程可控的实验室。如果你追求“一句话就能出商业级图片”,别折腾SD,买MJ或 Fooocus(另一个极简SD界面)更适合。但如果你享受控制每一个像素的乐趣,或者有复杂创作需求,SD WebUI会给你无限的回报。
常见问题
SD WebUI对显卡要求高吗?显存不够怎么办?
最低配置是NVIDIA显卡6GB显存,推荐8GB。如果是6GB显存,建议用SD1.5模型或SDXL配合Tiled VAE插件。AMD显卡也能用,但性能大约是N卡同级的60%,而且有些插件不兼容。苹果M1/M2芯片也能运行,但速度较慢(生成一张1024图片约30-60秒)。显存不够时,降低分辨率(比如用768x768)、开启Tiled VAE、使用Euler a采样器(步数少)是最有效的三个解决方案。
为什么我生成的图片总是模糊或者畸形?
99%的情况是负面提示词没写好,或者CFG Scale不对。首先检查负面提示词是否包含“ugly, deformed, blurry, low quality, extra limbs, bad anatomy”这些基础词。其次检查CFG Scale是否在5-9之间,过高或过低都会导致畸变。最后考虑是否是模型问题——有些社区模型训练不充分,会稳定产生畸形,换一个高下载量的模型试试。
SD WebUI和Midjourney哪个更好?
没有“更好”,只有“更合适”。Midjourney的优势在于:无需显卡、界面极简、审美在线、一致性强。SD WebUI的优势在于:完全免费、无限次数、可控性极高、可以本地运行、有海量模型可自定义。核心区别是:MJ是摄影师,SD是画家。如果你要快速拿图发社交媒体或做商业展示,用MJ;如果要做批量生成、风格实验、精细控制,用SD WebUI。
提示词应该用中文还是英文?
截至2026年6月,SD原生模型基本只训练英文提示词,用中文效果很差。但有两个办法:一是用 SD3.5 模型,它对中文有原生理解能力;二是安装 Prompt Translator 插件,它会把中文自动翻译成英文再喂给SD。但最稳定的方案还是学几个核心英文单词(masterpiece, best quality, cinematic, realistic等),配合翻译工具写提示词。
如何提高生成速度?
提高速度的方法按效果排序:1)降低分辨率(从1024降到768);2)减少迭代步数(从20降到12-15);3)使用Euler a采样器;4)安装 Latent Diffusion Super-Resolution 插件(先低分辨率快速生成,再放大);5)升级显卡(从RTX 3060升到4060,速度能提升约50%)。另外,NVIDIA的Tensor Cores能加速,建议在设置里开启“FP16”或“FP8”模式。
常见问题
SD WebUI对显卡要求高吗?显存不够怎么办?
最低配置是NVIDIA显卡6GB显存,推荐8GB。如果是6GB显存,建议用SD1.5模型或SDXL配合Tiled VAE插件。AMD显卡也能用,但性能大约是N卡同级的60%,而且有些插件不兼容。苹果M1/M2芯片也能运行,但速度较慢(生成一张1024图片约30-60秒)。显存不够时,降低分辨率(比如用768x768)、开启Tiled VAE、使用Euler a采样器(步数少)是最有效的三个解决方案。
为什么我生成的图片总是模糊或者畸形?
99%的情况是负面提示词没写好,或者CFG Scale不对。首先检查负面提示词是否包含“ugly, deformed, blurry, low quality, extra limbs, bad anatomy”这些基础词。其次检查CFG Scale是否在5-9之间,过高或过低都会导致畸变。最后考虑是否是模型问题——有些社区模型训练不充分,会稳定产生畸形,换一个高下载量的模型试试。
SD WebUI和Midjourney哪个更好?
没有“更好”,只有“更合适”。Midjourney的优势在于:无需显卡、界面极简、审美在线、一致性强。SD WebUI的优势在于:完全免费、无限次数、可控性极高、可以本地运行、有海量模型可自定义。核心区别是:MJ是摄影师,SD是画家。如果你要快速拿图发社交媒体或做商业展示,用MJ;如果要做批量生成、风格实验、精细控制,用SD WebUI。
提示词应该用中文还是英文?
截至2026年6月,SD原生模型基本只训练英文提示词,用中文效果很差。但有两个办法:一是用 SD3.5 模型,它对中文有原生理解能力;二是安装 Prompt Translator 插件,它会把中文自动翻译成英文再喂给SD。但最稳定的方案还是学几个核心英文单词(masterpiece, best quality, cinematic, realistic等),配合翻译工具写提示词。
如何提高生成速度?
提高速度的方法按效果排序:1)降低分辨率(从1024降到768);2)减少迭代步数(从20降到12-15);3)使用Euler a采样器;4)安装 Latent Diffusion Super-Resolution 插件(先低分辨率快速生成,再放大);5)升级显卡(从RTX 3060升到4060,速度能提升约50%)。另外,NVIDIA的Tensor Cores能加速,建议在设置里开启“FP16”或“FP8”模式。
读完文章了?试试提效录自建工具
全部免费 · 无需登录 · 打开即用