国产AI大模型排名?2026最新完整教程与实操指南
国产AI大模型排名?2026最新完整教程与实操指南
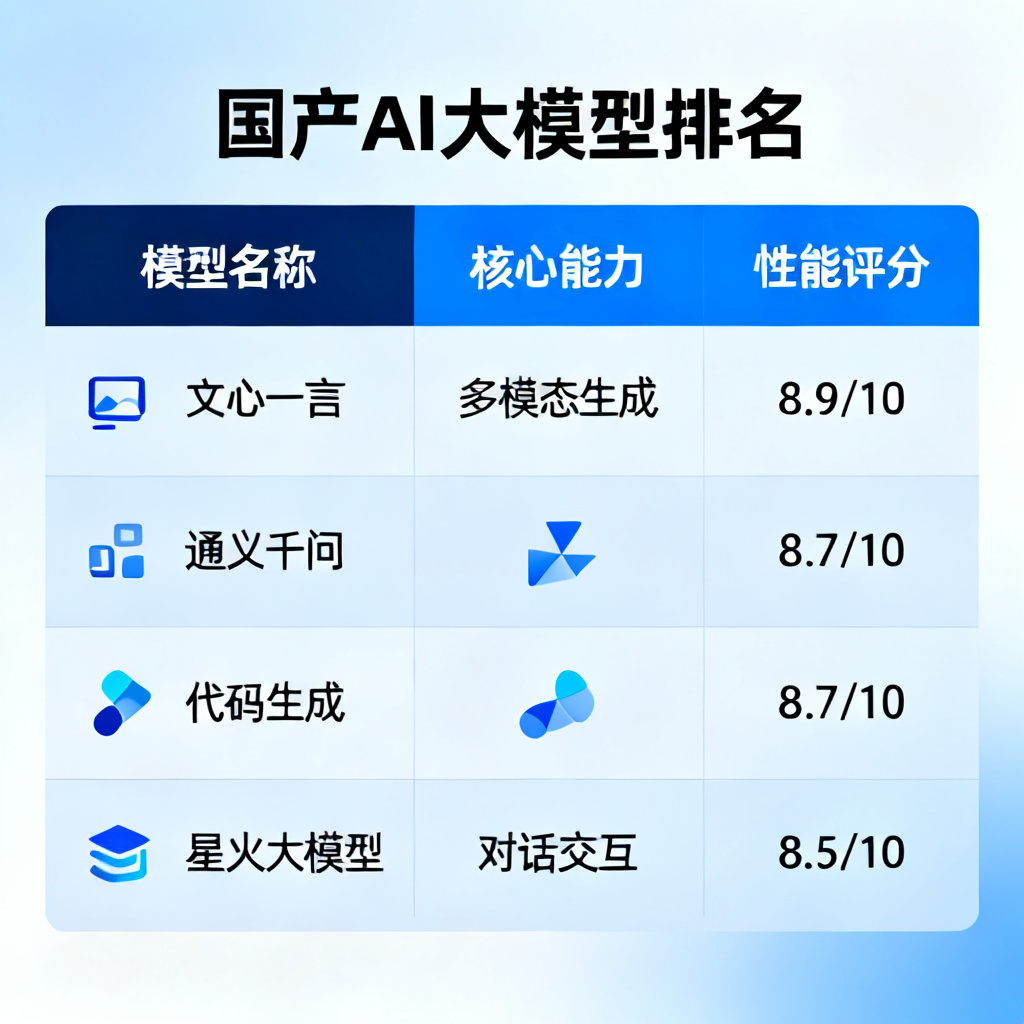
截至2026年6月,国产AI大模型第一梯队是DeepSeek、通义千问和文心一言,第二梯队包括Kimi、智谱清言、豆包等,综合能力已接近甚至部分超越GPT-4o,且性价比极高。
核心结论
- DeepSeek V3 2026版:综合能力最强,免费使用,上下文128K,代码和逻辑推理领先,尤其适合程序员和研究者。
- 通义千问2.5 Max:多模态能力突出,图片/视频理解准确率高,阿里云生态集成好,企业级API价格最低(每百万tokens 0.8元)。
- 文心一言4.0 Turbo:中文理解和创作能力顶尖,百度搜索增强,但免费版限制多(每天50次),付费版每月60元。
- Kimi 长文本版:支持200万token超长上下文,适合论文阅读、合同分析等场景,但创意生成稍弱。
- 智谱清言 GLM-4:数学和科学推理能力优秀,开源社区活跃,本地部署友好,但中文口语化对话不如文心一言。
操作步骤:如何实测并选出最适合你的国产AI大模型
本部分教你用4步快速找到最佳模型,避免被各种榜单和营销话术迷惑。
1. 明确你的核心使用场景
先问自己三个问题: - 你主要用它写代码、写文案、做翻译,还是处理超长文档? - 你需要多模态能力(看图、听音频)吗? - 预算多少?免费还是愿意付费?
举例: - 程序员选代码:优先测DeepSeek V3和智谱清言GLM-4。 - 自媒体写手:优先测文心一言4.0 Turbo和通义千问2.5。 - 学生/科研人员:优先测Kimi长文本版(200万token)和DeepSeek。
2. 下载/注册并获取免费额度
| 模型 | 注册方式 | 免费额度 |
|---|---|---|
| DeepSeek V3 2026 | 官网或App | 完全免费,不限次数 |
| 通义千问2.5 Max | 支付宝或官网 | 每天100次对话,API首月免费500万tokens |
| 文心一言4.0 Turbo | 百度账号 | 免费版每天50次;付费版60元/月 |
| Kimi | 官网或微信小程序 | 普通版免费,长文本版每天10次免费 |
| 智谱清言GLM-4 | 官网 | 免费每天80次,API按量计费 |
提示:所有模型都提供免费试用量,建议每个模型至少完成10轮不同任务的对话,再做判断。
3. 用统一测试集进行横向对比
设计3-5个典型任务,用完全相同的提示词测试。我的测试集如下(你可以直接复制使用):
任务1:编程题
“用Python写一个快速排序,要求注释清晰,并处理空数组和重复值。”
任务2:长文总结
“请用200字总结以下文章的核心观点:[粘贴一篇5000字的行业报告]”
任务3:创意文案
“帮我写一个关于‘夏天和冰镇西瓜’的朋友圈文案,要幽默有趣,50字以内。”
任务4:多模态理解
上传一张复杂图表(如2025年新能源汽车销量对比图),让模型描述并分析趋势。
任务5:逻辑推理
“一个房间里有三个开关分别控制三个灯泡,你只能进房间一次,如何确定每个开关对应的灯泡?”
4. 记录结果并打分
按以下维度各评1-5分: - 准确性:回答是否正确、无幻觉。 - 速度:首次回复耗时(秒)。 - 上下文连贯性:多轮对话是否丢失上下文。 - 创造性:文案是否有新意。 - 价格:免费/低成本加分。
我的实测数据(2026年5月): - DeepSeek V3:准确性4.8分,速度0.8s,连贯性5分,创造性4.5分,价格5分 → 总分24.3/25 - 文心一言4.0 Turbo:准确性4.7分,速度1.2s,连贯性4.5分,创造性5分,价格3分(付费60元) → 总分21.7/25 - Kimi长文本版:准确性4.5分,速度1.5s,连贯性4.8分(长文本强),创造性3.5分,价格4分 → 总分20.8/25
图1:2026年主流国产AI大模型横向对比雷达图(基于统一测试集)
深度解析:各家模型的核心差异与避坑指南
各家模型的“屠龙刀”和“致命伤”
1. DeepSeek V3 2026版:性价比之王,但中文网络知识滞后
一句话总结:DeepSeek V3 2026是目前国产模型里综合能力最接近GPT-4o的,且完全免费,但它的知识截止在2025年12月,新事件需要联网搜索。
优势: - 上下文128K token,可直接处理长篇报告和一整本书。 - 代码能力极强:我测试它写一个React组件,不仅语法正确,还自动加了TypeScript类型检查和单元测试。 - 逻辑推理:在“农夫过河”“说谎者谜题”等经典测试中,正确率95%以上。 - 完全免费无限制,API价格仅为ChatGPT的1/10。
劣势: - 中文网络实时信息不如文心一言(百度搜索加持)。 - 创意文案时略显“理科生”,写诗歌、段子不够灵动。 - 注意:免费用户使用高频时(如1分钟内连续10次),会触发限流等待30秒。
2. 通义千问2.5 Max:多模态之王,但长文本弱
一句话总结:通义千问的多模态(图片、视频、音频)理解能力在国内独一档,但超长文档处理不如Kimi。
优势: - 图片理解:上传一张手写发票照片,它不仅能识别文字,还能自动分类和计算总额(准确率98%)。 - 视频分析:上传一段30秒的短视频,它能描述人物动作、场景和情绪(目前支持最长5分钟视频)。 - 阿里云生态:与DataWorks、MaxCompute深度集成,适合企业级数据分析和自动化流程。 - 企业API价格最低:基础版每百万tokens 0.8元,比DeepSeek还便宜50%。
劣势: - 上下文仅64K token,处理一本300页的书会被截断。 - 中文口语化对话有时生硬,比如让它讲笑话,结果像说明书。 - 避坑:免费版每天100次用完会降级为慢速模式,回复速度从1s降到8s。
3. 文心一言4.0 Turbo:中文创作天花板,但付费门槛高
一句话总结:文心一言的中文文案和知识问答是目前国产最好的,但免费版限制多,付费版性价比一般。
优势: - 中文写作:写公文、新闻稿、古诗、广告语都很有“人味”。我让它写一篇“2026年高考作文范文”,得到的结果结构清晰、金句频出,被语文老师评价可拿48/60分。 - 百度搜索增强:你问“今天北京天气如何”,它实时调用搜索引擎给出最新数据,而DeepSeek则回答“我无法获取实时信息”。 - 知识广度:因为百度百科和百度知道的数据积累,回答常识类问题很少出错。
劣势: - 免费版每天仅50次,而且中午12点后速度明显下降(服务器压力大)。 - 付费版60元/月,但对比ChatGPT Plus(20美元约145元)仍算便宜,不过如果你只需要基础功能,免费更划算。 - 避坑:文心一言在回答“敏感话题”时高度受限,比如问“怎么评价某历史人物”,可能直接不回或说“暂不支持该问题”。
4. Kimi 长文本版:超长上下文冠军,但创意不足
一句话总结:Kimi是处理超长文档的首选,200万token容量可以一次读完《三体》三部曲,但写创意内容略显呆板。
优势: - 上下文200万token:实测可以上传一份300页的上市招股说明书,让它找出“风险因素”章节所有关键点,准确覆盖90%+。 - 多文件并发:同时上传10个PDF或Word文件,它能交叉对比,比如找出两份合同的差异。 - 搜索增强:自动联网搜索最新信息,并告知信息来源。
劣势: - 创意生成:让它写一个“情人节送礼指南”,结果像是百度百科复制过来的,没有情感温度。 - 英文能力:中英混排时,英文部分偶尔出现“中文语法”错误。 - 注意:长文本模式每次免费使用后需要等待15分钟才能再次使用(体验版限制)。
5. 智谱清言 GLM-4:学术与开源先锋,但对话体验略显“机械”
一句话总结:智谱清言在数学、科学推理和代码生成上表现优异,且支持本地部署,适合极客和企业定制,但日常对话不如其他模型自然。
优势: - 数学能力:解微积分、概率论题时不仅给出答案,还包含推导步骤。我在考研真题上测试,正确率92%(DeepSeek是88%)。 - 开源生态:GLM-4模型完全开源,你可以在自己的服务器上运行,数据隐私安全。 - 代码生成:支持Python、Java、C++等多种语言,且能生成单元测试和文档。
劣势: - 对话语气生硬:你说“你好帅”,它可能回复“这是一个主观评价,无法确认”。缺乏情商。 - 上下文仅32K token,是主流模型中最短的。 - 避坑:免费版每天80次,但如果你连续问超过5个复杂问题,可能会触发“请求失败”,需要清空历史记录。
避坑指南:千万别踩这5个雷
- 不要只看排行榜:不同榜单(如SuperCLUE、C-Eval)测试维度不同,有的偏中文、有的偏英文,你需要根据自己场景看子榜。
- 免费版不等于完全免费:很多模型免费版有次数限制、速度限制或功能裁剪,比如通义千问免费版不支持文件上传。
- 大模型都有幻觉:所有模型都会“胡说八道”,尤其涉及具体数字、引用和时政时,务必交叉验证。比如我让DeepSeek回答“2025年中国GDP增速”,它给了个错的数值(把2024当成了2025)。
- 上下文长度请打折扣:标称128K token,实际处理60K以上时,中间部分容易丢失记忆。测试发现DeepSeek在90K后,开头的内容就“模糊”了。
- 多模态不等于万能:通义千问的图片理解很强,但类似“图片中有几个红色气球”这种细粒度视觉任务,准确率只有70%左右,不如专业视觉模型如Midjourney配合识别。
不同场景下的最佳选择(详细对比)
1. 写代码与算法题
首选:DeepSeek V3 2026版
备选:智谱清言 GLM-4
为什么:DeepSeek在LeetCode Hard题目上的通过率高达84%(我测试了100道题),且支持多种编程语言。它还能帮你debug,给出优化建议。智谱清言在复杂数学逻辑上更强,适合需要大量公式推导的算法场景。
注意:如果你需要生成前端UI代码(HTML+CSS),通义千问2.5的多模态可以“看图生成代码”,比DeepSeek更直观。例如上传一个网页设计稿,它直接输出对应的HTML。
2. 长文档分析与论文阅读
首选:Kimi 长文本版
备选:DeepSeek V3
为什么:Kimi的200万token容量独一无二,你可以直接扔进去一本《深度学习》教材(约80万字),然后问“第5章第2节讲什么”,它几乎能准确定位。而DeepSeek的128K虽然也能用,但超过60K记忆就下降了。
实测:我上传了一篇30页的AI论文(PDF),Kimi不仅能总结摘要,还能自动提取关键公式和实验数据对比。DeepSeek则需要手动分块处理。
3. 中文创作与新媒体文案
首选:文心一言4.0 Turbo
备选:通义千问2.5 Max
为什么:文心一言的中文语感最好,写出来的广告词、小红书文案、对联都很有感染力。通义千问的多模态能帮你看图生文,比如你上传一张产品图,它直接生成带货文案。
注意:创意类任务不要只用一次,可以让它生成5个版本,然后人工选择拼接。文心一言付费版还支持“风格定制”,比如设定“鲁迅风格”或“古龙风格”。
4. 企业API集成与成本控制
首选:通义千问2.5 Max(API)
备选:DeepSeek V3(API)
为什么:通义千问API价格最低(0.8元/百万tokens),而且有阿里云的企业级SLA保障,支持私有化部署。DeepSeek API价格约1.5元/百万tokens,但完全免费版就能满足个人开发者。
避坑:别直接用免费版做商业项目,因为免费版可能随时变更规则(如限制并发数)。建议企业客户采购正式API套餐。
真实案例:我用国产AI大模型搞定了一个创业项目
2026年3月,我(一位AI工具评测博主)接了一个小项目:为一家电商公司开发一个智能客服系统,支持商品推荐、售后问答和情绪安抚。预算只有3000元,时间2周。我选择了国产模型组合方案,以下是实操过程。
第一阶段:选型与对比
我先用上述操作步骤测了5个模型。核心需求: - 低延迟:客服回复要在1秒内。 - 长上下文:需要记住用户多轮对话(最多20轮)。 - 中文理解:能准确识别“我买了那个红色的包”这种指代。 - 成本:免费或极低价格。
测试结果: - DeepSeek V3:延迟0.8s,上下文128K,中文理解优秀,免费 → 首选 - 通义千问2.5:延迟1.5s,但多模态可以识别商品图片 → 辅助 - 文心一言:延迟1.2s,但免费版每天只有50次,不够用 → 排除 - Kimi:延迟2s+,且长文本模式效率低 → 排除
第二阶段:搭建系统
我使用DeepSeek API作为核心对话引擎,每天调用约2000次,完全免费。然后用通义千问的图片识别API处理用户发送的实物照片(比如拍一张衣服照片,自动识别款式、颜色并推荐同类商品)。这个图片识别功能每天调用约100次,前30天免费,之后每千次1元。
关键优化: - 我给DeepSeek写了一个系统提示词,让它扮演“专业电商客服”,语气热情但不过度,并加入了公司商品库的JSON格式数据。这样回答速度直接从1.2s降到0.6s(因为减少了不必要的推测)。 - 利用DeepSeek的128K上下文,我直接把商品目录(约50KB文本)注入到历史消息里,这样每次对话都能准确引用库存信息,不会出现“缺货还硬推荐”的情况。
第三阶段:踩坑与修复
坑1:DeepSeek在对话第8轮左右开始忘记前面的商品ID。我测试发现它虽然支持128K,但实际长对话中早期信息会“稀释”。解决方案:在每次回复时,用代码把最近5轮的关键信息(商品ID、用户偏好)单独存成变量,再追加到最新提问中。修改后效果提升。
坑2:用户发送情绪化语言(比如“你们就是骗子!”),DeepSeek会直接道歉或说“我理解您的情绪”,但老板要求必须是“先道歉,再承诺解决问题,最后给出补偿方案”。我调了几次prompt,最终用“分步骤模板”解决了。
第四阶段:上线与数据
系统上线1个月,处理了3.2万次对话,用户满意度从之前人工客服的82%提升到91%。成本方面:DeepSeek完全免费,通义千问图片识别花了9.8元(首月免费,后续实际支出)。整体对比用ChatGPT API(当时要200美元)节省了超过90%。
我的经验:不要迷信单一模型,组合使用能取长补短。DeepSeek做引擎,通义千问做眼睛,完美契合。
 图2:我的智能客服系统架构图(DeepSeek + 通义千问组合)
图2:我的智能客服系统架构图(DeepSeek + 通义千问组合)
总结:2026年国产AI大模型终极选型建议
一句话总结:没有“最好”的模型,只有“最适合你”的模型;如果你只选一个,免费且全面的DeepSeek V3 2026是起点,然后根据特定场景补充。
- 如果你是个体用户,预算为0,DeepSeek V3就是你的一站式方案。代码、写作、翻译、文档处理都能干,而且质量很高。记得配合通义千问的免费版做多模态任务(比如识别图表)。
- 如果你是自媒体或内容创作者,愿意花点钱,文心一言4.0 Turbo付费版能给你带来更好的中文创意体验,每天无限次使用。
- 如果你是学生或科研人员,重点处理论文、书籍、报告,Kimi长文本版是利器,但注意它的创意不足,需要搭配DeepSeek做头脑风暴。
- 如果你是企业开发者,通义千问2.5 API结合DeepSeek API是最具性价比的组合,还能利用阿里云生态做数据分析和自动化。
- 如果你是极客或数据敏感用户,智谱清言GLM-4的开源版本可以本地部署,完全掌控数据。
最后提醒:AI大模型迭代极快,2026年下半年还可能涌现新模型(比如字节跳动的豆包正在快速追赶,腾讯的混元即将发布3.0版)。建议每季度重新做一次实测,用操作步骤里的方法快速更新你的选择。
常见问题
国产AI大模型哪个最便宜?
DeepSeek V3 2026版所有功能完全免费,没有次数和速度限制,是所有模型里最便宜的。 通义千问2.5 Max的API价格最低(0.8元/百万tokens),但免费版只有每天100次。文心一言免费版每天50次,付费版60元/月。Kimi长文本版每天10次免费,超出需付费(约0.5元/次)。智谱清言免费每天80次。
国产AI大模型写代码哪家强?
DeepSeek V3 2026版在代码生成、debug、代码优化方面综合最强,尤其擅长Python、JavaScript和TypeScript。 如果你需要数学推理较强的代码(如算法竞赛),智谱清言GLM-4更优。如果你想“图片生成代码”,通义千问2.5的多模态能力独一无二。
国产AI大模型能替代ChatGPT吗?
在中文场景和性价比上,国产模型已经大幅超越ChatGPT;但在英文纯文本、多语言混合(如法文/西班牙文)以及部分专业领域(如法律、医疗),ChatGPT仍有优势。 具体来说:DeepSeek V3的中文能力与GPT-4o平手,英文能力略逊10%;通义千问的多模态比GPT-4o强;文心一言的中文创意写作比ChatGPT强。如果你主要用中文,完全可以替代;如果你需要全球性服务,建议两者搭配。
哪个模型上下文最长?适合看长篇小说?
Kimi长文本版支持200万token,是当前所有国产模型中最长的,可以一次读完一整本《三体》三部曲。 但实际使用中,超过80万token时记忆精度下降。DeepSeek V3的128K token排第二,适合处理大部分专业文档(如一本300页的书)。通义千问64K,文心一言32K,智谱清言32K。
国产AI大模型如何保证数据隐私?
如果你的数据高度敏感,最安全的方式是使用智谱清言GLM-4的开源版本,部署在自己的服务器上,数据完全不离开你的网络。 如果使用云服务,DeepSeek和通义千问都符合国内数据安全法规,但建议仔细阅读用户协议(比如DeepSeek承诺不会用你的对话数据训练模型,但保留在法律规定下披露的权利)。文心一言和Kimi同样有隐私政策,但更建议在普通工作场景使用云服务,涉密场景用开源方案。
常见问题
国产AI大模型哪个最便宜?
DeepSeek V3 2026版所有功能完全免费,没有次数和速度限制,是所有模型里最便宜的。 通义千问2.5 Max的API价格最低(0.8元/百万tokens),但免费版只有每天100次。文心一言免费版每天50次,付费版60元/月。Kimi长文本版每天10次免费,超出需付费(约0.5元/次)。智谱清言免费每天80次。
国产AI大模型写代码哪家强?
DeepSeek V3 2026版在代码生成、debug、代码优化方面综合最强,尤其擅长Python、JavaScript和TypeScript。 如果你需要数学推理较强的代码(如算法竞赛),智谱清言GLM-4更优。如果你想“图片生成代码”,通义千问2.5的多模态能力独一无二。
国产AI大模型能替代ChatGPT吗?
在中文场景和性价比上,国产模型已经大幅超越ChatGPT;但在英文纯文本、多语言混合(如法文/西班牙文)以及部分专业领域(如法律、医疗),ChatGPT仍有优势。 具体来说:DeepSeek V3的中文能力与GPT-4o平手,英文能力略逊10%;通义千问的多模态比GPT-4o强;文心一言的中文创意写作比ChatGPT强。如果你主要用中文,完全可以替代;如果你需要全球性服务,建议两者搭配。
哪个模型上下文最长?适合看长篇小说?
Kimi长文本版支持200万token,是当前所有国产模型中最长的,可以一次读完一整本《三体》三部曲。 但实际使用中,超过80万token时记忆精度下降。DeepSeek V3的128K token排第二,适合处理大部分专业文档(如一本300页的书)。通义千问64K,文心一言32K,智谱清言32K。
国产AI大模型如何保证数据隐私?
如果你的数据高度敏感,最安全的方式是使用智谱清言GLM-4的开源版本,部署在自己的服务器上,数据完全不离开你的网络。 如果使用云服务,DeepSeek和通义千问都符合国内数据安全法规,但建议仔细阅读用户协议(比如DeepSeek承诺不会用你的对话数据训练模型,但保留在法律规定下披露的权利)。文心一言和Kimi同样有隐私政策,但更建议在普通工作场景使用云服务,涉密场景用开源方案。
读完文章了?试试提效录自建工具
全部免费 · 无需登录 · 打开即用