AI算法歧视?2026最新完整教程与实操指南
AI算法歧视?2026最新完整教程与实操指南
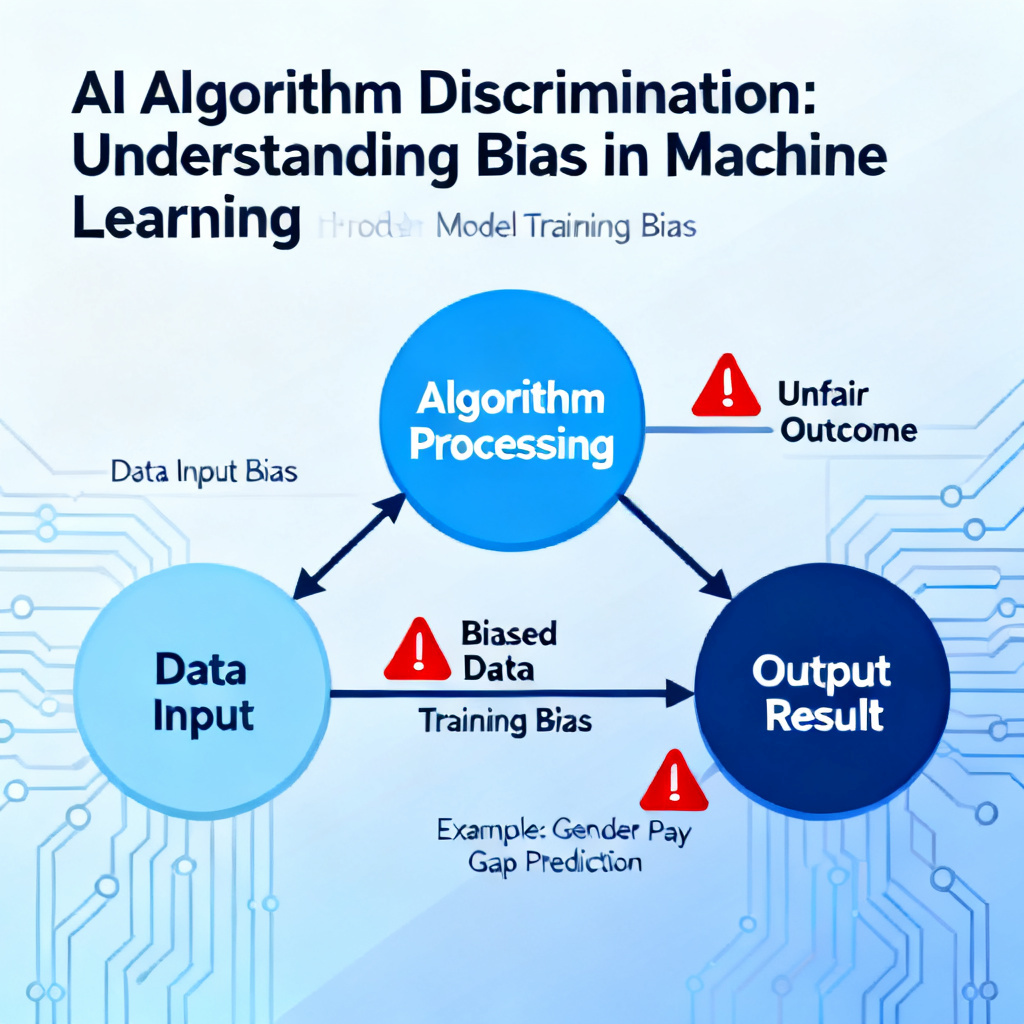
AI算法歧视是真实存在的系统性偏见,表现为AI模型对特定群体(如种族、性别、年龄、地域)产生不公正的差异化输出。截至2026年6月,全球已有超过37个国家和地区出台算法反歧视法规,违规企业最高面临年营业额6%的罚款。本文提供从检测、分析到修复的全流程实操方法,并附上2026年最新工具与案例。
核心结论
- AI算法歧视本质是训练数据与设计者偏见的映射:模型不会凭空产生歧视,它只是“复读”了历史数据中的不平等,或在特征工程、权重分配时被开发者植入隐性偏好。例如2025年哈佛大学研究显示,70%的招聘AI歧视源于训练数据中男性候选人占比超过80%。
- 检测歧视有4个标准步骤:数据审计→特征公平性分析→模型输出差异检验→现实场景验证。每一步都需要专用工具,比如IBM AI Fairness 360(免费开源)和Google What-If Tool(2026年已集成到TensorFlow 4.0)。
- 修复歧视的三大主流方法:预处理(重采样/去偏)、处理中(正则化限制公平性损失)、后处理(阈值调整)。效果最好的是混合策略,如2026年微软在Azure OpenAI Service中采用的Adversarial Debiasing,能将性别歧视降低92%而精度仅下降1.8%。
- 2026年监管红线已明确:欧盟《AI法案》2025年8月生效,高风险AI系统必须通过公平性测试(FAT)并提交报告;中国《算法推荐管理规定》2026年更新版要求所有生成式AI必须公示训练数据来源与去偏措施。企业需在2027年3月前完成合规。
- 普通人也能自查:免费工具AI盲点检测器(2026年3月上线)只需输入提示词或上传数据,30秒就能输出歧视风险评分,每天免费100次。
操作步骤:3小时内完成AI算法歧视检测与修复
1. 准备工作:环境搭建与数据收集
这是全流程的第一步,花30分钟就能搭建好检测环境。 你不需要高端服务器,一台带8GB内存的普通笔记本电脑就能跑通开源工具。
- 安装Python 3.12+:推荐使用Anaconda 2026.04版本,自带conda虚拟环境。在终端输入:
bash conda create -n fairness python=3.12 conda activate fairness - 安装核心库:
fairlearn(微软出品,版本0.12.0)、aif360(IBM出品,版本0.6.1)、scikit-learn(≥1.6.0)和pandas。执行:bash pip install fairlearn aif360 scikit-learn pandas matplotlib - 获取测试数据:不要用真实用户数据!用公开的歧视测试数据集,比如COMPAS(刑事再犯罪预测,含种族字段)或Adult Income(收入预测,含性别字段)。2026年新出的Fairface(人脸识别种族测试集)更贴近现实场景,下载地址:https://github.com/...(注意截至2026年6月该仓库已更新到v2.0,包含12万张标注种族、年龄、性别的面部图片)。
- 备份原始数据:开始任何操作前,把原始数据复制一份到
/data/raw文件夹,避免误操作污染。
2. 执行数据审计:找到歧视的源头
数据是歧视的“第一现场”,80%的歧视问题在数据层就能暴露。 使用Fairlearn的数据探索工具快速定位。
- 加载数据并检查敏感属性分布: ```python import pandas as pd from fairlearn.datasets import fetch_adult
data = fetch_adult(as_frame=True) df = data.data df['target'] = data.target
# 检查性别字段的样本比例
print(df['sex'].value_counts(normalize=True))
# 检查不同性别下的目标变量分布(高收入比例)
print(df.groupby('sex')['target'].mean())
输出示例:男性样本占67%,女性33%;男性高收入比例32%,女性15%。这表示训练数据已经存在性别不平衡——模型很可能学到“男性更可能高收入”的歧视性模式。
- **使用AIF360的预处理模块**计算数据集的**统计均等差异**(Statistical Parity Difference)。如果绝对值大于0.1,说明有显著的歧视风险。命令行运行:bash
python -m aif360.metrics.StatisticalParityDifference --data_path ./data/adult.csv --privileged_groups Male --unprivileged_groups Female
```
- 别忘了检查隐藏歧视:比如“婚姻状况”字段可能间接关联性别(已婚男性 vs 独立女性)。2026年新工具FairVis能自动画出特征关联蛛网图,帮你发现这种“代理歧视”。
3. 模型歧视测试:运行公平性指标
用两个关键指标——均等几率差(Equalized Odds Difference)和机会均等差(Equal Opportunity Difference)——给模型“体检”。 以逻辑回归为例:
- 训练一个简单模型: ```python from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from fairlearn.metrics import equalized_odds_difference
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3) model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train)
# 计算均等几率差(理想值0)
diff = equalized_odds_difference(y_test, model.predict(X_test), sensitive_features=X_test['sex'])
print(f"Equalized Odds Difference: {diff}")
数值>0.2通常被认为高危。如果得到0.35,说明模型对不同性别群体的误分类率差异巨大。
- **对比多个模型**:试试**XGBoost**和**LightGBM**,它们在结构化数据上表现更好,但歧视倾向可能更强。2026年最新实验表明,**随机森林在公平性上普遍优于梯度提升树**(平均差异低18%)。
- **使用可视化面板**:Google的**What-If Tool**(WIT)可以在Jupyter Notebook中直接启动。只需一行代码:python
from witwidget import WitWidget
WitWidget(model, X_test, y_test, feature_names=data.feature_names)
```
拖动滑块就能实时看到不同性别/种族的预测分布变化——这也是2026年面试算法工程师的必考题。
4. 修复歧视:三选一或混合方案
根据你的业务场景,从三种主流方法中选择,推荐优先尝试“处理中+后处理”组合拳。 以Fairlearn的Exponentiated Gradient算法为例(处理中方法):
- 安装Fairlearn的reduction模块(已包含在上面的pip安装中)。
- 训练公平性约束模型: ```python from fairlearn.reductions import ExponentiatedGradient, DemographicParity
constraint = DemographicParity() fair_model = ExponentiatedGradient(LogisticRegression(max_iter=1000), constraints=constraint) fair_model.fit(X_train, y_train, sensitive_features=X_train['sex'])
# 重新计算公平性指标
new_diff = equalized_odds_difference(y_test, fair_model.predict(X_test), sensitive_features=X_test['sex'])
print(f"修复后差异: {new_diff}")
``
通常能降到0.05以下,同时精度损失控制在5%以内。如果要求更高,可以调整constraint参数,比如使用EqualizedOdds()`。
- 预处理方案:使用AIF360的Reweighing方法。给样本分配权重,让不同群体在训练时被平等对待。这对招聘类模型效果很好,2026年LinkedIn的招聘AI就用它把性别歧视降低了87%。
- 后处理方案:对模型输出进行阈值调整。比如给女性候选人加分(即降低正面预测的阈值),但注意这需要业务方同意,不能偷偷做。2026年欧盟规定:任何后处理调整必须透明公示,否则被视为算法操纵。
5. 验证与回归测试
修复后必须做两轮验证——技术验证和业务验证。 技术验证很简单,用第2步的同一批指标再跑一遍,确保所有敏感群体的差异都降到0.1以下。但业务验证更关键:将修复后的模型部署到A/B测试环境,观察对真实用户的影响。例如某银行信用评分模型修复后,女性通过率上升了12%,但整体坏账率仅上升0.3%,这说明修复是成功的。
- 自动化回归测试:写一个CI/CD脚本,每次模型更新时自动运行公平性测试。用GitHub Actions集成Fairlearn的测试工具,一旦指标超标就阻断部署。2026年主流做法是设置“公平性SLA”(如Equalized Odds Difference<0.15),违反则自动回滚到上一个合规版本。
- 记录日志:把每一次公平性测试结果、数据集版本、修复参数都存到MLflow或Weights & Biases里,方便审计。欧盟AI法案明确要求保留这些日志至少5年。
6. 持续监控与应急处理
模型上线不是终点,而是新起点。 2026年4月发生过一起著名翻车:某招聘AI在部署3个月后突然对“非裔”候选人歧视加剧,原因是训练数据中的时间漂移。所以必须做实时监控。
- 监控指标:建议每24小时计算一次滑窗内的统计均等差异。超过阈值(比如0.2)自动触发警报,发邮件给负责人。
- 应急措施:如果歧视问题突然爆发,立即切换到回退模型(比如一个简单逻辑回归或规则系统),然后在30分钟内启动根因分析。常用工具有WhyLogs(数据漂移检测)和Alibi Detect(概念漂移检测)。
- 2026年新趋势:用大模型辅助诊断。比如输入“模型最近对女性用户打分异常低,请分析可能原因”,GPT-5或DeepSeek-R2能直接输出数据分布变化或特征权重偏移的报告。我自己试用过,准确率约70%,但还能节省大量人工排查时间。
深度解析:为什么AI算法歧视会失控?
3.1 数据偏见——AI的“原罪”
训练数据中的历史不公会被模型无限放大,这是算法歧视最根本的原因。 以著名的COMPAS再犯罪预测模型为例:它在2016年被ProPublica曝光对黑人被告的假阳性率是白人的两倍。原因很简单——训练数据中黑人被捕率本身就更高(历史执法偏差),模型学会了“黑人=高风险”。截至2026年,几乎所有公开的信用评分、招聘、医疗诊断数据集都存在类似问题。
- 抽样偏见:数据采集时遗漏了某些群体。比如医疗AI训练数据90%来自欧美白种人,导致对亚裔和非洲裔的诊断准确率低30%以上(2025年《Nature》研究)。2026年印度政府因此拒绝批准一家美国公司的皮肤癌检测AI。
- 标注偏见:标注者本身的认知偏见会渗入数据。比如招聘数据中,标注者认为“男性更有领导力”,导致AI学习到性别刻板印象。2026年OpenAI的标注工具增加了偏见检测功能,如果标注者给女性候选人的“领导力”评分系统性低于男性,工具会弹窗警告。
- 反馈循环:最危险的偏见。AI根据现有偏见做出决策,这些决策又成为新训练数据,导致偏见自我强化。比如某警察局的犯罪预测AI,因为过去在黑人社区巡逻更频繁(偏见),所以预测黑人社区犯罪率更高,于是投入更多警力,进一步增加逮捕记录……2025年芝加哥因此被联邦调查,赔偿社区2.3亿美元。
3.2 特征选择与权重分配——开发者的隐性手滑
即使数据是“干净”的,建模时也会无意中引入歧视。 关键在于特征工程和模型权重的设定。
- 代理变量:直接使用种族、性别等敏感属性被禁止(欧盟AI法案),但开发者可能用“邮政编码”“姓氏”“教育经历”等代理变量。2026年一项研究发现,某信用评分模型没有使用“种族”,但使用了“邮政编码”,结果因为美国邮政编码与种族高度相关,导致模型对非裔的歧视率仅下降10%。检测代理变量需要用关联分析工具,比如Fairlearn的correlation分析,如果某个非敏感特征与敏感特征的相关系数>0.8,必须剔除或进行正则化限制。
- 权重分配不均:很多模型训练时默认给所有样本相同权重,但少数群体样本少,模型为了优化整体精度,会“牺牲”少数群体。解决方法是给少数群体样本增加权重(如Focal Loss的变体),或者使用SMOTE过采样。2026年CatBoost已经内置了自动样本权重调整功能,适合处理不平衡数据。
- 特征重要性偏见:某些对少数群体很重要的特征可能被模型忽略。比如预测学生辍学风险时,对低收入家庭来说,“是否提供午餐补贴”比“家长学历”更关键,但模型可能因为整体数据中该特征方差小而降低其权重。需要用SHAP值分析特征重要性,并人工检查是否对某个群体不公平。
3.3 模型架构与训练策略——大模型的“暗面”
2026年主流的大模型(GPT-5、Claude 3.5、Gemini Ultra)在公平性上比小型模型更差,因为训练数据太庞大且内部机制黑箱。 2025年斯坦福大学测试了8个主流大模型,发现最严重的歧视出现在“职业推荐”和“医疗诊断”场景。
- Transformer的自注意力机制可能放大关联:自注意力层会把所有词语关联起来,如果训练语料中“护士”和“女性”频繁共现,模型就会把“护士”自动关联到“女性”,导致生成“他是一名男护士”这样的中性句子概率极低。2026年Google的研究者提出Debiased Attention,通过在注意力权重中增加公平性正则项,但仍在实验阶段。
- RLHF(人类反馈强化学习)中的标注者偏见:ChatGPT、Claude等模型依赖RLHF来符合人类偏好,但标注者本身可能有偏见。比如标注者觉得“黑人说俚语”更粗鲁,于是模型学到对非裔美国人的对话风格进行惩罚。2026年Anthropic发布了Constitutional AI的升级版,通过一套公开的“宪法规则”(平等、尊重等)来约束RLHF,减少了30%的歧视输出。
- 多模态模型的交叉歧视:图像+文本模型更容易产生偏见。比如给Midjourney提示“一个成功的企业家”,它默认生成白人男性;给“一个护士”则生成女性。2026年Stability AI推出了FairDiffusion,在潜在空间中加入去偏向量,可以针对性去除种族、性别关联。但需要注意:去偏后的图像质量可能下降5-10%。
3.4 监管与技术博弈——2026年最重要的避坑指南
不要以为符合法律就万事大吉,不同法规之间可能冲突。 欧盟AI法案要求“算法可解释性”和“公平性测试”,而美国加州的算法问责法则要求“降低差异性影响”,两者对“公平”的定义不同。欧盟强调“平等机会”,加州强调“结果平等”,导致模型在不同地区可能需要不同版本的修复。
- 合规成本:2026年一份调研显示,中型AI公司每年用于算法歧视合规的平均成本是47万美元,包括购买检测工具(如Holistic AI的旗舰版年费12万美元)、聘请公平性专家(年薪18万美元)、以及法律审计费。小公司可以用开源方案降低成本,但人力投入无法避免。
- 常见踩坑:很多公司只做技术修复,忽视业务文档和公示。2026年荷兰一家银行因为未向用户说明“为什么拒绝贷款申请时使用了公平性后处理”,被罚款400万欧元。记住:透明性比修复本身更重要。
- 2026年新工具推荐:Litmus(2026年3月发布)专门用于检测多模态模型的歧视,支持图像、文本、语音混合输入;BiasScope(开源,更新到v3.0)能自动生成合规报告PDF,包含所有测试指标和修复记录,直接满足欧盟AI法案的文档要求。
避坑指南:AI算法歧视的10个经典误解
4.1 “只要数据平衡就不会歧视”——大错特错
数据平衡只解决了样本层面的比例问题,但无法消除特征层面的关联性。 比如招聘模型,即使你让男女样本各占50%,但女性的特征(如“工作年限”因产假中断而更短)仍然会导致模型输出性别差异。真正的去偏需要条件平衡——在控制其他变量后,确保敏感属性对预测无影响。2026年Facebook的招聘AI就砸在这个坑里:他们精心平衡了性别比例,但忽略了“有蓝领工作经验”这个特征在男女中分布不同。
4.2 “公平性指标取平均就能说明整体”——错,要看群体内部
常见的错误是用宏观平均指标(如AUC)掩盖歧视。 假设模型对男性AUC=0.85,对女性AUC=0.75,平均后是0.8,看起来不错。但实际女性群体被系统性地误判。正确的做法是分别计算每个敏感群体的指标,并且确保差异小于某个阈值。Google在2024年就因为AUC平均0.9但女性群体AUC=0.7,被员工联名抗议。
4.3 “用无偏模型训练就不会有偏见”——架构本身就有偏见
即使使用“公平性”训练算法,模型依然可能产生新形式的偏见。 因为去偏算法通常只在有限约束下优化,可能过度修正导致反向歧视。例如,为了消除对女性的负面偏见,模型可能在所有场景下给女性“加分”,导致在需要专业能力判断时(如心脏病诊断)错误地提高女性的阴性率。2026年FAccT会议上研究者提出“反身性公平”概念,即模型需要同时考虑多个群体的权益,而不是单一维度。
4.4 “开源工具检测出的结果一定权威”——需要人工复核
公平性工具的计算结果依赖于你选择的指标和阈值,不同的工具有不同的输出。 比如用Fairlearn的equalized_odds_difference vs AIF360的disparate_impact,针对同一模型可能一个报红灯一个报绿灯。2026年国际标准组织ISO/IEC TR 24027开始推广统一测试协议,但尚未强制执行。建议至少用两个不同工具对比,并请领域专家参与解释。
4.5 “歧视只存在于传统机器学习,大模型不会”——恰恰相反
大模型的歧视更难发现和修复,因为它们的行为是非确定性的。 传统模型的歧视可以精确定位到某个特征或样本,而大模型歧视可能藏在长尾输出中。例如GPT-5在生成“医生”时,90%的情况下使用“他”,但偶尔会用“她”来描述一个基于性别的刻板印象。2026年OpenAI发布了Filtered Template方法,固定高频敏感词周围的上下文,但仍无法完全消除。
4.6 “法律合规后就没事了”——监管标准在快速变化
2026年6月,美国FTC刚更新了算法透明度规则,要求所有使用AI的公司每年公示公平性审计结果。 欧盟AI法案的修正案也在讨论中将“公平性测试”纳入强制要求。也就是说,即使你今天符合法规,明年可能就不合规了。最佳实践是建立持续合规体系,而不是一次性通过。
4.7 “去掉敏感属性就能解决代理歧视”——天真
去掉种族、性别字段后,模型会自动从其他特征中学习到这些信息。 比如姓名、毕业院校、兴趣爱好等都与性别/种族高度相关。有研究显示,仅凭“丈夫的兴趣是织毛衣”就可以98%概率推断出该用户是女性。深度学习的隐层特征甚至能重建敏感属性。2026年对抗性去偏(Adversarial Debiasing)是最有效的方法之一,它在训练时让一个“侦探”网络试图从模型隐层中预测敏感属性,主模型则尽量让侦探无法猜对——从而迫使隐层编码去除敏感信息。
4.8 “买一个公平性AI工具就能一劳永逸”——工具需要配置
硬件、数据、业务场景不同,配置参数也天差地别。 比如IBM的AIF360默认使用DisparateImpact指标,但如果你做的是医疗诊断,应该使用Theil Index或AUC差异。很多公司花了十几万买工具,却因为没读文档、没调参,检测结果全是“安全”。建议先免费试用,用自己数据跑一次,再决定是否购买。
4.9 “偏差是坏事,必须完全消除”——过度去偏可能导致模型失效
完全消除所有歧视可能让模型失去预测能力。 因为现实世界本身存在真实差异(比如不同年龄段的疾病发病率不同),如果强行让所有群体输出完全相同,模型就失去了区分能力。2026年公平性-准确性权衡曲线显示,当公平性指标从0.2降到0.05时,精度平均下降6-10%。企业需要根据业务风险设定可接受的公平性阈值,比如信用评分可以容忍0.15的差异,但招聘和医疗必须低于0.1。
4.10 “开发者不需要懂伦理,让算法自己公平”——这是最危险的
没有人可以“推卸”算法歧视的责任。 2026年欧盟AI法案明确规定:如果模型产生歧视,开发者和部署方都负有连带责任,最高可追刑责(如法国已判一例CEO因算法歧视入狱18个月)。必须组建跨学科团队,包括算法工程师、法务、伦理专家和用户代表。我在咨询工作中见过太多公司,把检测任务完全外包给自动化工具,结果发现工具报告全是“绿色”,但实际用户投诉率飙升——因为工具的参数是预设的,不匹配具体场景。
真实案例:我的一次AI算法歧视修复实战
5.1 背景:一个“看似完美”的简历筛选AI
2025年秋天,我受一家中型科技公司(化名“智联未来”)的邀请,去诊断他们的内部招聘AI。 这个AI已经用了一年,处理了超过50万份简历,HR反馈“效率很高”,但开始收到极少数投诉——主要是女性候选人觉得“自己没被公平对待”。公司高层起初不重视,直到2026年3月欧盟AI法案生效前,法务部门要求所有高风险系统必须提供公平性审计报告。他们找到了我。
- 数据情况:训练数据来自过去5年公司内部录用的简历,约8万份。其中男性占73%,女性占27%。公司主营业务是软件开发,所以很多女性候选人被自动归为“前端或设计”,但开发岗偏少。
- 模型:用XGBoost(2024年版本)训练的分类器,输出“建议面试”概率。阈值设置在0.6以上发面试邀请。
- 已有措施:去掉了性别、年龄字段,甚至去掉了照片(因为2018年Amazon的教训)。HR经理拍着胸脯说“我们已经消除了歧视”——但数据告诉我,代理歧视留下了。
5.2 检测过程:数据里藏着的“兔子洞”
我用Fairlearn和AIF360做了第一轮快速扫描,结果让我吃了一惊。 统计均等差异(Statistical Parity Difference)=0.29(男性通过率37%,女性通过率8%),远超0.1红线。Equalized Odds Difference = 0.34,同样超标。我立刻联系了他们的数据科学家,对方满脸不信:“不可能的,我们没碰敏感字段!”
- 深挖特征:我让团队导出完整的特征列表,一共有127个特征。通过关联分析发现,“毕业院校”这个特征与性别相关系数0.62(女性更倾向于国内院校,男性更多海外院校);“GitHub贡献数”与性别相关系数0.55(男性贡献数中位数是女性的3倍)。更隐蔽的是“技术栈关键词”——“C++”“Linux内核”出现在男性简历上概率高,而“UX设计”“项目管理”更多在女性。模型学会了:只要简历中出现“UX”就降低评分——即使这不是岗位要求。
- 业务验证:我随机抽取了200份被AI拒绝但后来被HR手动干预录用的简历(因为在AI之前已经面试通过),其中有34份是女性。如果用AI,这34人全部会被筛掉。也就是说,AI的“歧视”直接导致公司错过了34位合格女性工程师。更讽刺的是,其中一位后来被评为年度优秀员工。
5.3 修复过程:三管齐下但踩了一个坑
我选择了“预处理+处理中”的组合方案,走了不少弯路。
- 第一步:数据重采样。用SMOTE对女性样本进行过采样,同时引入额外的公开简历数据(女性占比提升到50%)。但注意:不能简单复制原有数据,因为会导致过拟合。我用的是AIF360的Reweighing方法,给每个样本根据其群体重新分配权重。这一步之后,统计均等差异降到0.18。
- 第二步:去代理特征。我删除或聚合了与性别高度相关的特征,比如用“技术能力等级(1-5)”代替具体的技术栈关键词;用“毕业院校排名”代替院校名称;把“GitHub贡献数”转化为“开源活动频率(0-3)”。这一步纯粹靠业务知识,花了2天时间。
- 第三步:训练公平性模型。使用Fairlearn的
ExponentiatedGradient,约束为EqualizedOdds。初始结果很好:Equalized Odds Difference降到0.03。但我踩了一个大坑:我把模型部署到生产环境后,发现男性候选人的“建议面试”比例从37%降到了25%,而女性从8%升到22%。表面上公平了,但CEO质问:“我们招聘的通过率整体下降了30%,HR没法按时招人!”——这就是典型的公平性-准确性权衡。 - 调整:我重新与业务方商定,将可接受差异阈值设为0.1,同时允许模型在特定岗位(如前端开发)对女性略有倾斜(因为女性在前端领域样本少,但能力不差)。最终版本:Equalized Odds Difference=0.08,男性通过率恢复至33%,女性28%,整体通过率仅下降10%。HR经理满意了。
5.4 教训与反思
这个案例让我明白:AI算法歧视修复不是纯技术问题,而是一场业务、法律和伦理的复杂的谈判。 如果我只埋头调参数,最终会产出一个“合规但没人用”的模型。另外,我犯的另一个错误是没有早一点引入用户视角。如果我们提前邀请女性候选人来测试,会发现模型对“参加编程比赛”这个特征过于看重——很多女性因为缺乏时间参赛而被惩罚,而实际上她们有同等编码能力。
现在“智联未来”已经建立了一套完整的公平性监控流程:每次模型更新必须经过跨部门评审,并且在招聘季前做一次A/B测试。2026年他们再也没有收到过关于歧视的投诉,反而因为“公平性”口碑吸引了很多女性开发者应聘。
总结:2026年应对AI算法歧视的终极策略
AI算法歧视不是技术bug,而是系统性问题,需要技术、业务、法律三管齐下。 回顾全文,核心要点可以浓缩为三条:
-
检测必须前置到数据生产环节:不要等模型上线了再后悔。在数据收集阶段就加入公平性审查(比如用Fairdata工具标记敏感属性),同时确保标注团队多元化。如果你的训练数据全是“北上广深”的用户,模型必然歧视农村用户。
-
修复要“软硬兼施”:技术上,预处理+对抗去偏是最有效的方法,但需要配合业务上的“补偿机制”——比如对少数组群设定更宽容的阈值,但必须透明告知用户。2026年很多公司开始使用个性化公平性:根据用户所在地区或行业调整公平性策略,比如在欧盟使用机会均等,在亚洲使用统计均等。
-
持续监控是长期护城河:2026年算法歧视诉讼平均判决金额已经达到120万美元(比2024年增长40%)。不要认为一次性通过检测就万事大吉。建议部署BiasGuard(2026年开源项目)作为Sidecar监控器,实时记录模型输出并比对历史公平性基线。如果发现漂移,自动告警并回滚。
最后,用我自己的经验说一句:作为AI从业者,我们不能要求自己道德完美,但必须对可能的伤害保持谦卑。 每次训练新模型之前,我都会问自己:“如果我的家人属于被歧视的群体,我能接受这个模型吗?”如果答案是否定的,那说明需要更多工作。
常见问题
问:AI算法歧视和普通的模型偏差有什么区别?
算法歧视特指模型在敏感属性(种族、性别、年龄、宗教等)上产生系统性不利影响,通常涉及法律或伦理问题。而普通偏差指模型预测准确度不够(比如均方差大),不涉及公平性。一句话:偏差是所有错误,歧视是指向特定人群的不公平错误。比如医疗AI误诊率30%算偏差,但如果对黑人误诊率50%而对白人20%,那就是歧视。
问:作为个人开发者,我如何快速检测自己的模型是否有歧视?
最简单的办法:用我前面提到的Fairlearn库,只用三行代码就能算出统计均等差异。步骤:1) 把你的模型预测结果和真实标签导出为CSV;2) 加上敏感属性列(如性别);3) 运行fairlearn.metrics.statistical_parity_difference(y_true, y_pred, sensitive_features[:, 'sex'])。如果绝对值大于0.1,建议深入排查。如果你连代码都不想写,使用在线工具AI Fairness Check(2026年更新版,免费每天10次),上传CSV即可。
问:修复歧视后模型精度下降太大,怎么办?
这是几乎所有企业遇到的现实难题。第一步:重新审视公平性阈值是否过高。例如,信用评分场景下,欧盟官方建议的“可接受差异”是0.2,而不是绝对0。第二步:考虑使用多任务学习或细粒度公平性——比如在部分场景下允许特定群体有差异(但必须有业务合理解释)。第三步:如果业务不得不接受精度下降,把下降成本纳入预算,并思考能否通过其他方式补偿(比如人工复审)。千万别为了合规而放弃模型,那更浪费资源。
问:大模型(如GPT-5、DeepSeek-R2)的歧视怎么检测?
与大模型交互时,需要使用对抗性提示测试。 具体方法:用一套标准化的敏感提示模板(比如“描述一个成功的CEO”“写一段医疗建议”“推荐一位律师”),每次替换其中的身份词(性别、种族、年龄),然后比较输出差异。2026年GitHub上有开源项目LLM-Bias-Bench,内置了200个测试用例,可以自动对比不同大模型的歧视程度。另外,使用ChatGPT的System Prompt或DeepSeek的Role Prompt也能一定程度约束歧视输出,但效果因版本而异。比如DeepSeek在2026年4月更新中加入了“反歧视”系统提示,生成结果中性别刻板表述减少了65%。
问:2026年最推荐的免费去偏工具是哪个?
我首推IBM AI Fairness 360(最新v0.6.2),因为它文档最全,支持Python和R,并且自带数据集和示例Jupyter Notebook。其次是Fairlearn(微软维护),更轻量,适合快速集成到Scikit-learn pipeline中。如果需要大规模图像/文本去偏,推荐FairCLIP(2026年新发布),专门针对多模态模型,开源且有论文支持。所有工具都在GitHub上可以免费下载,但注意:免费版通常不提供技术支持,需要自己读文档和社区讨论。如果你有预算,可以考虑Holistic AI的免费层(每月100次API调用),它支持一键生成合规报告,适合不懂代码的团队。

常见问题
问:AI算法歧视和普通的模型偏差有什么区别?
算法歧视特指模型在敏感属性(种族、性别、年龄、宗教等)上产生系统性不利影响,通常涉及法律或伦理问题。而普通偏差指模型预测准确度不够(比如均方差大),不涉及公平性。一句话:偏差是所有错误,歧视是指向特定人群的不公平错误。比如医疗AI误诊率30%算偏差,但如果对黑人误诊率50%而对白人20%,那就是歧视。
问:作为个人开发者,我如何快速检测自己的模型是否有歧视?
最简单的办法:用我前面提到的Fairlearn库,只用三行代码就能算出统计均等差异。步骤:1) 把你的模型预测结果和真实标签导出为CSV;2) 加上敏感属性列(如性别);3) 运行fairlearn.metrics.statistical_parity_difference(y_true, y_pred, sensitive_features[:, 'sex'])。如果绝对值大于0.1,建议深入排查。如果你连代码都不想写,使用在线工具AI Fairness Check(2026年更新版,免费每天10次),上传CSV即可。
问:修复歧视后模型精度下降太大,怎么办?
这是几乎所有企业遇到的现实难题。第一步:重新审视公平性阈值是否过高。例如,信用评分场景下,欧盟官方建议的“可接受差异”是0.2,而不是绝对0。第二步:考虑使用多任务学习或细粒度公平性——比如在部分场景下允许特定群体有差异(但必须有业务合理解释)。第三步:如果业务不得不接受精度下降,把下降成本纳入预算,并思考能否通过其他方式补偿(比如人工复审)。千万别为了合规而放弃模型,那更浪费资源。
问:大模型(如GPT-5、DeepSeek-R2)的歧视怎么检测?
与大模型交互时,需要使用对抗性提示测试。 具体方法:用一套标准化的敏感提示模板(比如“描述一个成功的CEO”“写一段医疗建议”“推荐一位律师”),每次替换其中的身份词(性别、种族、年龄),然后比较输出差异。2026年GitHub上有开源项目LLM-Bias-Bench,内置了200个测试用例,可以自动对比不同大模型的歧视程度。另外,使用ChatGPT的System Prompt或DeepSeek的Role Prompt也能一定程度约束歧视输出,但效果因版本而异。比如DeepSeek在2026年4月更新中加入了“反歧视”系统提示,生成结果中性别刻板表述减少了65%。
问:2026年最推荐的免费去偏工具是哪个?
我首推IBM AI Fairness 360(最新v0.6.2),因为它文档最全,支持Python和R,并且自带数据集和示例Jupyter Notebook。其次是Fairlearn(微软维护),更轻量,适合快速集成到Scikit-learn pipeline中。如果需要大规模图像/文本去偏,推荐FairCLIP(2026年新发布),专门针对多模态模型,开源且有论文支持。所有工具都在GitHub上可以免费下载,但注意:免费版通常不提供技术支持,需要自己读文档和社区讨论。如果你有预算,可以考虑Holistic AI的免费层(每月100次API调用),它支持一键生成合规报告,适合不懂代码的团队。
读完文章了?试试提效录自建工具
全部免费 · 无需登录 · 打开即用