Ollama本地部署:2026运行DeepSeek指南
一、Ollama是什么?2026年为什么人人都在用?
Ollama 是一款开源的本地大模型运行工具,2024年发布后两年GitHub Star已突破90K,成为个人开发者和企业落地本地AI的事实标准。Ollama官网(ollama.com)提供一键安装包,Ollama教程核心就一句话:在你电脑上一键运行Llama 3、Qwen 2.5、DeepSeek-V3等开源大模型,不需要联网、不用付API费、对话数据100%留在本地。
很多人第一次接触Ollama会问”它和Hugging Face Transformers、vLLM、LM Studio有什么区别?“——Ollama的定位是**“消费级的本地大模型工具链”**,把模型加载、量化、推理、API服务全部封装成一个命令,把”跑大模型”从”程序员专属”变成”普通用户也能上手”。
为什么2026年Ollama突然爆火?三个原因:
- 数据隐私 + 合规刚需:越来越多企业(金融、医疗、政企、律所)禁止把内部数据传给ChatGPT/Claude等海外API,Ollama本地部署成了唯一合规选项。一个典型场景是律所的合同审查——客户合同绝对不能出公司网,用Ollama + Qwen2.5本地跑就完全合规。
- 模型效果追平云端:2025-2026年开源模型能力大爆发,DeepSeek-V3、Qwen2.5-72B、Llama 3.1-405B这些旗舰开源模型的效果已经接近GPT-4o,本地跑完全够用。更多模型对比可以参考2026 Q3大模型横评。
- 硬件门槛大幅降低:8G显存的RTX 3060就能流畅跑7B模型,量化技术(Q4/Q5)让消费级显卡也能跑30B+的大模型。Mac用户用M1/M2/M3的统一内存架构同样可以本地推理。
Ollama使用的最大魅力在于”门槛低、上限高”:新手可以30分钟跑通第一个对话,高手可以基于Modelfile做自定义模型微调和RAG集成。无论你是想给公司搭一个私有AI客服,还是单纯想离线玩玩DeepSeek,Ollama都是当前最省心的选择。
Ollama官网入口:ollama.com(国内访问可能稍慢,也可以直接搜”Ollama GitHub”进入仓库),GitHub地址是 github.com/ollama/ollama,里面有详细文档、API参考、社区Discussions。
二、Ollama vs ChatGPT vs 在线API:到底怎么选?
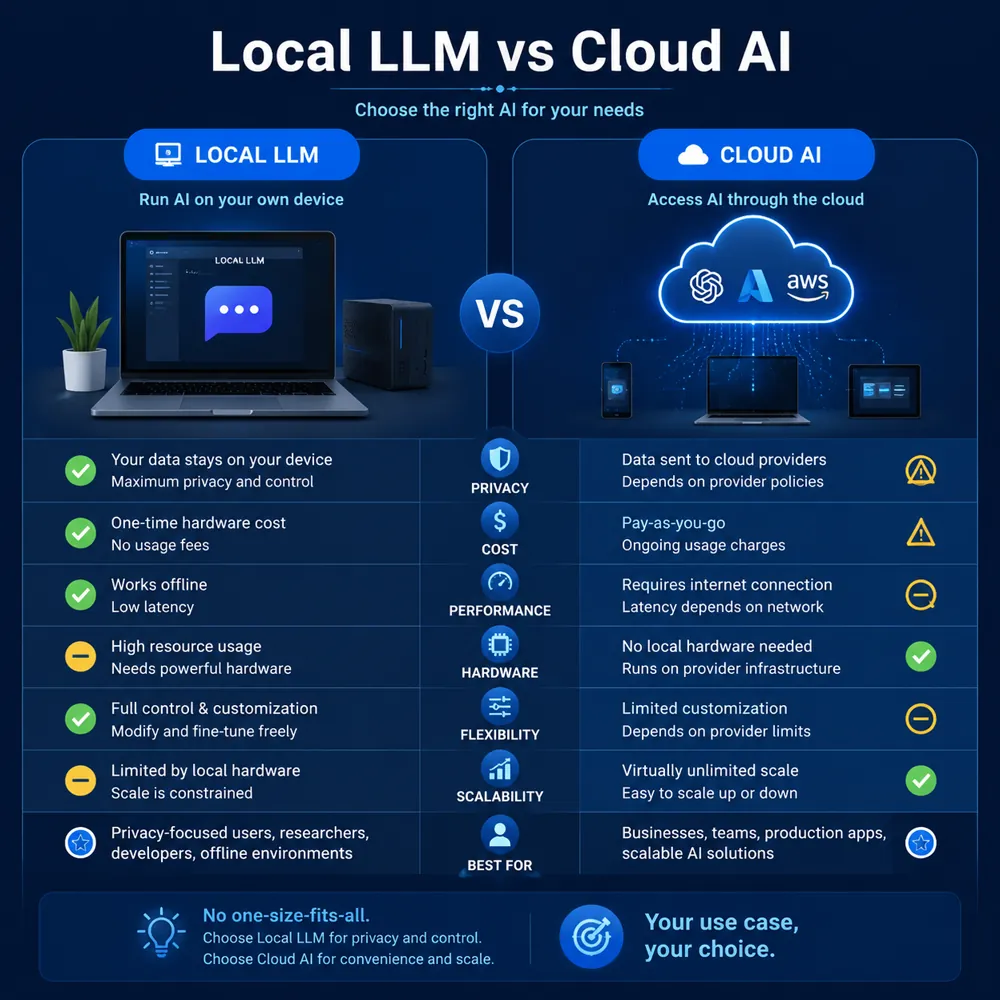
很多新手第一反应是”Ollama能替代ChatGPT吗?“,答案是场景化选择。Ollama使用的核心价值不是”完全替代ChatGPT”,而是”在合适的场景下提供更安全、更经济、更可控的AI能力”。下面这张表帮你3秒决策:
| 维度 | Ollama本地 | ChatGPT Plus | 在线API(DeepSeek/通义) |
|---|---|---|---|
| 部署位置 | 你的电脑/服务器 | OpenAI云端 | 模型厂商云端 |
| 数据安全 | 100%私有 | 数据传给OpenAI | 数据传给国内厂商 |
| 月费成本 | 0元(电费+硬件折旧) | $20/月 | 按Token付费,约¥10-100/月 |
| 响应速度 | 依赖硬件(10-50 token/s) | 快(云端GPU) | 快(云端GPU) |
| 模型效果 | 7B-70B开源模型 | GPT-4o顶级 | DeepSeek-V3接近GPT-4 |
| 适合场景 | 敏感数据/学习研究/离线 | 日常对话/创作 | 轻量API集成/小团队 |
实操建议:
- 公司内部数据 + 隐私合规 → Ollama本地(首选,金融/医疗/政企/律所几乎都用这个方案)
- 日常写作/翻译/学习 → ChatGPT/Claude(效果最好,模型迭代最快)
- 程序开发 → Ollama + Qwen2.5-Coder(代码不出公司,搭配AI编程软件排行里的Cursor体验更佳)
- 创业小团队 → DeepSeek API(性价比高,¥1/百万tokens,比GPT-4便宜200倍)
- 复杂RAG/企业应用 → Dify + Ollama(参考Dify教程做可视化工作流)
- 学术研究/学习大模型原理 → Ollama本地(想看模型怎么推理、改System Prompt、加LoRA微调,本地最方便)
一个真实案例:某跨境电商团队用Ollama本地部署Qwen2.5-14B做”商品标题本地化翻译+多语种Listing生成”,2000个SKU的翻译从外包人工一周时间压缩到本地2小时,成本从¥5000降到¥10(电费),数据还不出公司。这种场景在Ollama出现之前是几乎不可能实现的。
三、硬件配置清单:你的电脑能跑哪些模型?

Ollama的优势是”够用就行”,下面是2026年实测的配置清单:
| 硬件档位 | 显存/内存 | 推荐显卡 | 可跑模型规模 | 典型速度 |
|---|---|---|---|---|
| 入门级 | 8G | RTX 3060 / M1 8G | 7B(Q4量化) | 15-25 token/s |
| 主流级 | 12G | RTX 4070 / M2 Pro 16G | 13B(Q4)/ 7B全精度 | 30-50 token/s |
| 进阶级 | 24G | RTX 4090 / M3 Max 36G | 30B(Q4)/ 13B全精度 | 40-60 token/s |
| 旗舰级 | 48G+ | A6000 / Mac Studio | 70B(Q4)/ 30B全精度 | 30-50 token/s |
关键参数解读:
- 显存决定上限:7B模型需要约4-6G显存,13B约8-10G,30B约16-20G,70B约40-48G。量化等级越低(如Q2)越省显存,但效果会下降。生产环境推荐Q4_K_M——在”效果/体积/速度”三者间取得最佳平衡。
- 统一内存的Mac很香:M1/M2/M3/M4的统一内存架构让GPU和CPU共享内存池,16G Mac实际可用显存≈16G,性价比极高。M3 Max 36G甚至可以本地跑30B全精度模型,对设计师、程序员非常友好。
- CPU也能跑:没有独显?Ollama支持纯CPU推理,只是速度慢5-10倍(5-10 token/s),但简单问答、写邮件、翻译短文完全够用。Mac的Apple Silicon芯片CPU/GPU统一调度,CPU推理比传统x86快很多。
- 量化模型推荐:生产环境用Q4_K_M或Q5_K_M量化,体积比全精度小一半以上,效果损失<3%。Ollama默认下载的就是Q4_K_M版本,对新手最友好。
- 硬盘别忽略:70B模型全精度约140G,Q4量化也要40G。建议预留至少模型体积2倍的SSD空间(系统+缓存+下载临时文件)。
- 散热很关键:长时间跑大模型显卡会持续满载,游戏本/迷你主机建议加散热底座;服务器部署一定要有机房空调。
四、Ollama完整安装教程(3分钟搞定)
4.1 Mac安装
一行命令搞定:
curl -fsSL https://ollama.ai/install.sh | sh安装完成后终端输入 ollama --version 验证,能输出版本号就说明OK。Mac用户建议同时开启Ollama的”开机自启”和”GPU加速”,首次启动会自动配置。
4.2 Linux安装
curl -fsSL https://ollama.ai/install.sh | shLinux用户如果是服务器部署,建议把Ollama做成systemd服务(脚本会自动配置),并监听 0.0.0.0:11434 供局域网内其他设备调用。
4.3 Windows安装
- 访问 ollama.com 下载
OllamaSetup.exe - 双击安装(默认装到C盘,建议改到D盘)
- 安装完成后PowerShell输入
ollama --version验证
Ollama官网入口上点 “Download for Windows” 即可下载最新版安装包,安装过程会自动配置PATH环境变量和开机自启服务。
4.4 验证安装
无论Mac/Linux还是Windows,安装完成后做这三步验证:
ollama --version查看版本(输出ollama version x.x.x)ollama serve启动服务(默认后台运行)curl http://localhost:11434看到Ollama is running即OK
如果端口11434被占用,可以改环境变量 OLLAMA_HOST=0.0.0.0:11435 换端口。
Ollama安装注意事项:
- Windows 11需要开启WSL2(Ollama底层走Linux子系统的CUDA),如果显卡驱动没装好推理会回退到CPU模式,速度骤降。
- 公司网络可能拦截
ollama.ai,可以设置代理export HTTPS_PROXY=http://your-proxy:port,或者用ghproxy等社区镜像。 - 模型默认下载到
~/.ollama/models(Mac/Linux)或C:\Users\xxx\.ollama\models(Windows),C盘空间紧张可以改OLLAMA_MODELS环境变量指向其他盘。 - Linux服务器部署建议用Docker运行Ollama,方便版本管理和迁移:
docker run -d -p 11434:11434 --gpus=all -v ollama:/root/.ollama ollama/ollama。 - 首次安装完Ollama会自动启动服务(监听127.0.0.1:11434),需要远程访问的话在
~/.ollama/config.json里改成0.0.0.0,并注意防火墙开放11434端口。
五、从0运行第一个模型(以DeepSeek-V3为例)
Ollama最爽的地方就是一行命令下载+运行。比如想跑DeepSeek:
# 1. 拉取DeepSeek-V3(671B参数,需要48G+显存)
ollama run deepseek-v3
# 显存不够?选蒸馏版:
ollama run deepseek-v3:671b-q4_K_M # 量化版,约380G(需要强机器)
ollama run deepseek-v3:70b # 蒸馏版,约40G
ollama run deepseek-v3:33b # 蒸馏版,约20G
ollama run deepseek-v3:8b # 蒸馏版,约4.6G(8G显存可跑)
# 2. 跑Qwen 2.5(中文效果更好)
ollama run qwen2.5:7b # 7B,约4.7G
ollama run qwen2.5:14b # 14B,约9G
ollama run qwen2.5:32b # 32B,约20G
ollama run qwen2.5:72b # 72B,约44G
# 3. 跑Llama 3.1(英文场景最佳)
ollama run llama3.1:8b
ollama run llama3.1:70b
# 4. 跑代码专用模型
ollama run qwen2.5-coder:32b # 阿里代码模型
ollama run deepseek-coder-v2:16b # DeepSeek代码模型
ollama run codellama:34b # Meta代码模型下载完成后Ollama会自动进入交互模式,直接在终端输入问题就能对话。输入 /bye 退出。
常用Ollama命令:
ollama list # 查看本地已下载的模型
ollama ps # 查看正在运行的模型
ollama rm deepseek-v3:8b # 删除指定模型
ollama show deepseek-v3:8b # 查看模型详细信息
ollama cp deepseek-v3:8b my-model # 复制模型(可改名+自定义配置)
ollama pull deepseek-v3:8b # 仅下载不运行(适合脚本化部署)
ollama stop deepseek-v3:8b # 停止某个正在运行的模型(释放显存)进阶玩法:自定义Modelfile
Ollama支持通过Modelfile创建”定制版模型”,类似Docker镜像的玩法。创建一个 Modelfile:
FROM qwen2.5:7b
# 设置系统提示词
SYSTEM "你是一个专业的中文技术写作助手,擅长用Markdown结构化输出"
# 设置温度参数(0-1,越高越发散)
PARAMETER temperature 0.7
PARAMETER top_p 0.9
# 限制上下文窗口
PARAMETER num_ctx 8192然后构建并运行:
ollama create my-writer -f Modelfile
ollama run my-writer这种方式特别适合做”行业专用模型”——比如给法律团队定制一个”合同审查助手”,给电商团队定制一个”商品描述生成器”。结合RAG知识库实战还能让模型回答公司内部文档问题,效果堪比ChatGPT Enterprise。
六、API调用 + Web UI集成
Ollama默认开启RESTful API(端口11434),可以无缝对接各种应用。
6.1 用curl调用API
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-v3:8b",
"prompt": "用一句话解释量子纠缠"
}'6.2 用Python调用
import requests
response = requests.post('http://localhost:11434/api/chat', json={
"model": "deepseek-v3:8b",
"messages": [{"role": "user", "content": "写一首关于秋天的七言绝句"}],
"stream": False
})
print(response.json()['message']['content'])6.3 搭配Web UI(强烈推荐)
光用终端太枯燥,给Ollama套个Web界面体验直接拉满。Ollama使用的最佳实践就是”Ollama + Web UI”的组合,前者负责推理引擎,后者负责交互体验。推荐3款:
- Open WebUI(最火,ChatGPT风格):
docker run -d -p 3000:8080 --name open-webui ghcr.io/open-webui/open-webui:main,浏览器打开http://localhost:3000即可,支持多用户、多模型切换、对话历史、联网搜索、知识库RAG。生产环境推荐加上--network=host共享Ollama端口。 - Lobe Chat(国内开源,UI漂亮):支持本地模型+云端API混用,markdown/代码/图表渲染完善,还支持插件市场和MCP协议。
- Page Assist(浏览器插件):Chrome扩展,在任何网页都能调Ollama,特别适合阅读外文文献、写邮件时随时调用AI辅助。
6.4 接入企业应用
如果要把Ollama接到公司业务系统(客服、知识库、CRM),可以搭配Dify教程做可视化工作流,或者参考RAG知识库实战做企业级问答系统。Dify内置了Ollama作为模型供应商,填上 http://localhost:11434 就能直接用。
七、Ollama 2026生态与价格方案

Ollama本身完全免费(MIT协议,可商用),但不同部署方式有不同成本:
| 部署方式 | 一次性投入 | 月运营成本 | 适合谁 |
|---|---|---|---|
| 个人PC | 0元(用现有电脑) | 电费30-50元 | 个人学习/极客玩家 |
| 游戏本/Mac | 0元 | 电费50-100元 | 自由职业/小工作室 |
| 本地服务器(RTX 4090) | 1.5-2万元 | 电费100-200元 | 中小企业/团队 |
| 多卡服务器(A6000×4) | 8-15万元 | 电费500-1000元 | 大型企业/AI实验室 |
| 云端GPU租赁(AutoDL/恒源云) | 0元 | 1500-5000元/月 | 短期项目/不想买硬件 |
省钱建议:
- 个人玩家直接用现有游戏本/台式机跑7B模型,0成本体验完整大模型能力——这是Ollama本地部署最爽的地方,把闲置显卡利用起来。
- 团队部署推荐”游戏本+远程访问”模式:把Ollama装在公司一台RTX 4090机器上,局域网内所有员工通过Open WebUI调用,硬件成本1.5万可以服务10-20人,对比ChatGPT Team ($25/人/月) 一年的费用,3个月回本。
- 项目制/短期需求:AutoDL、恒源云、阿里云弹性实例按小时租赁,4090约3-5元/小时,临时跑大模型非常划算。
- 想”鱼与熊掌兼得”:可以把”日常对话用ChatGPT + 内部敏感数据用Ollama”组合起来。Open WebUI支持同时配置Ollama和OpenAI API,前端无感切换。
- 关注Ollama官网(ollama.com)的版本更新:2026年Ollama团队在持续优化推理速度(新的Flash Attention实现、KV Cache优化),建议每个季度升级一次大版本,享受免费的性能提升。
八、总结 + 常见问题
一句话总结Ollama的价值:把”用大模型”从”月付$20+数据上云”变成”装个软件+本地运行”,让AI能力真正属于个人和企业。2026年如果你关心数据隐私、长期成本或AI自主可控,Ollama是必学工具。
学习路径建议:
- 第1天:装好Ollama,跑通
ollama run qwen2.5:7b对话 - 第3天:装Open WebUI,配置多模型切换
- 第7天:学会Python调用API,做自动化脚本
- 第14天:搭建RAG知识库(Ollama + LangChain + Chroma)
- 第30天:部署到服务器,公司内部全员使用
新手常见问题:
Q:Ollama下载模型很慢怎么办?
A:模型默认从GitHub下载,国内可能很慢。设置镜像:export OLLAMA_MIRROR=https://your-mirror.com(社区有ghproxy等加速方案)。
Q:模型效果不如ChatGPT怎么办? A:选对模型很关键。中文场景用Qwen2.5-72B或DeepSeek-V3,效果接近GPT-4o。也可以在Open WebUI里同时跑多个模型对比。
Q:可以商用吗? A:Ollama本身MIT协议可商用。但具体模型要看其协议——Llama 3.1社区协议允许月活7亿以下用户商用,Qwen 2.5允许商用,DeepSeek-V3 MIT协议完全开放。
Q:怎么更新Ollama?
A:Mac/Linux:curl -fsSL https://ollama.ai/install.sh | sh 重新执行。Windows:下载新版本安装包覆盖安装。
Q:Ollama和LM Studio、Jan有什么区别? A:LM Studio是GUI版Ollama,更适合完全不懂命令行的用户;Jan是新兴的本地AI客户端,UI更现代但生态还在完善。底层原理一样,新手任选一个即可。
相关阅读: