RAG入门到实战:2026搭建企业知识库
2026年,大模型企业落地最热的方向是什么?答案是RAG(Retrieval-Augmented Generation,检索增强生成)。无论是AI客服、企业知识库、文档问答,还是法律助手、医疗问诊,背后都跑着同一套RAG架构。Gartner 2026年报告预测,超过70%的企业大模型应用将基于RAG构建。本文从原理、选型、实战到商用方案,一篇讲透。
一、为什么RAG是2026年企业AI首选?
大模型有两个先天缺陷:知识陈旧(训练数据截止后一无所知)和幻觉编造(一本正经胡说八道)。比如你问GPT-4o”我们公司最新的报销政策是什么”,它要么说”我不了解贵公司”,要么会编一套听起来很合理但完全是假的规定。这在企业场景里是致命的。
传统Fine-tuning方案成本高、周期长、知识更新难——一次微调动辄几十万、训练数周,而且每次政策更新都要重新训练。RAG直接解决这两个问题——让大模型先”查资料”,再”写答案”,而且查的是你的资料、实时的资料。
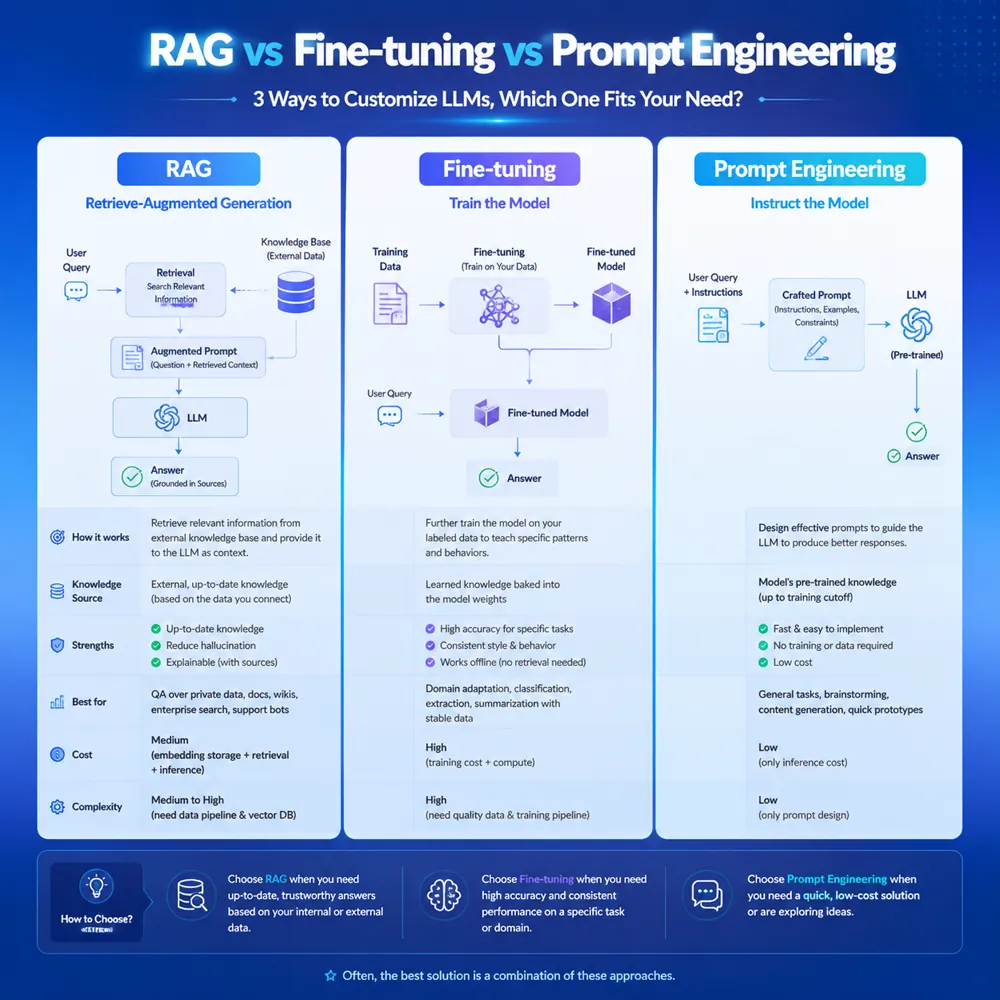
对比三种方案,RAG优势一目了然:
| 方案 | 知识更新速度 | 数据安全 | 实施成本 | 适合场景 |
|---|---|---|---|---|
| Fine-tuning | 极慢(重训数周) | 高 | 几十万级 | 风格/语气定制 |
| 传统搜索 | 实时 | 高 | 低 | 文档检索 |
| RAG | 实时 | 高 | 低 | 知识问答 |
RAG的核心价值可以归纳为四点:
第一,数据私有。你的产品手册、客户合同、内部SOP不会上传到公网大模型,数据完全留在自己的服务器里。这对金融、医疗、法律、政府等数据敏感行业是硬性要求。
第二,答案准确。RAG的答案永远基于检索到的真实资料,附带引用(cite),用户可以点击跳转到原文核对。不再是”AI说有就有”。
第三,持续学习。新增一份文档只需要5分钟——上传、切分、Embedding、入库,下次提问就能查到。完全不用重新训练模型。
第四,成本可控。RAG的核心组件Embedding和向量检索都是轻量操作,单次问答成本不到一分钱,比Fine-tuning便宜几个数量级。
详细对比见向量数据库选型指南。
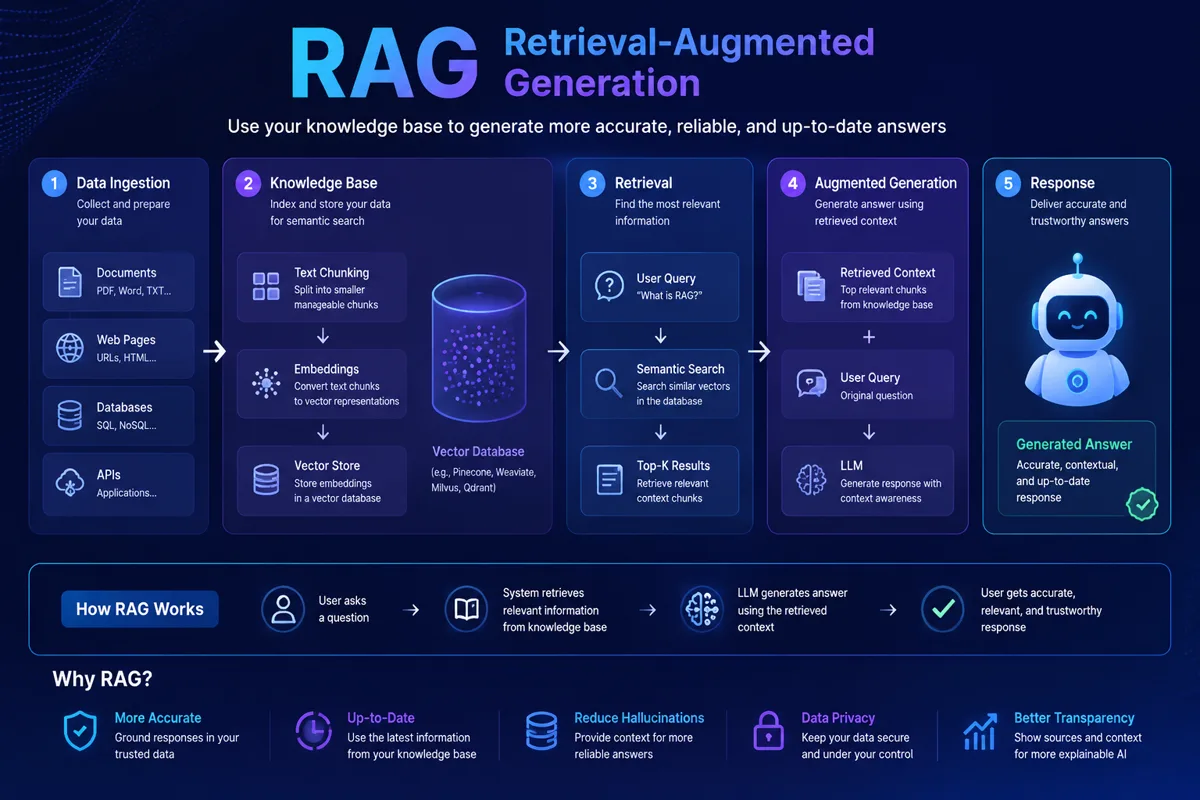
二、RAG工作原理:3步看懂核心架构
RAG的运行流程可以拆成”离线入库”和”在线问答”两条线,两者解耦,互不干扰。这也是RAG能”实时更新知识”的关键——入库是异步批处理,问答是同步实时检索。
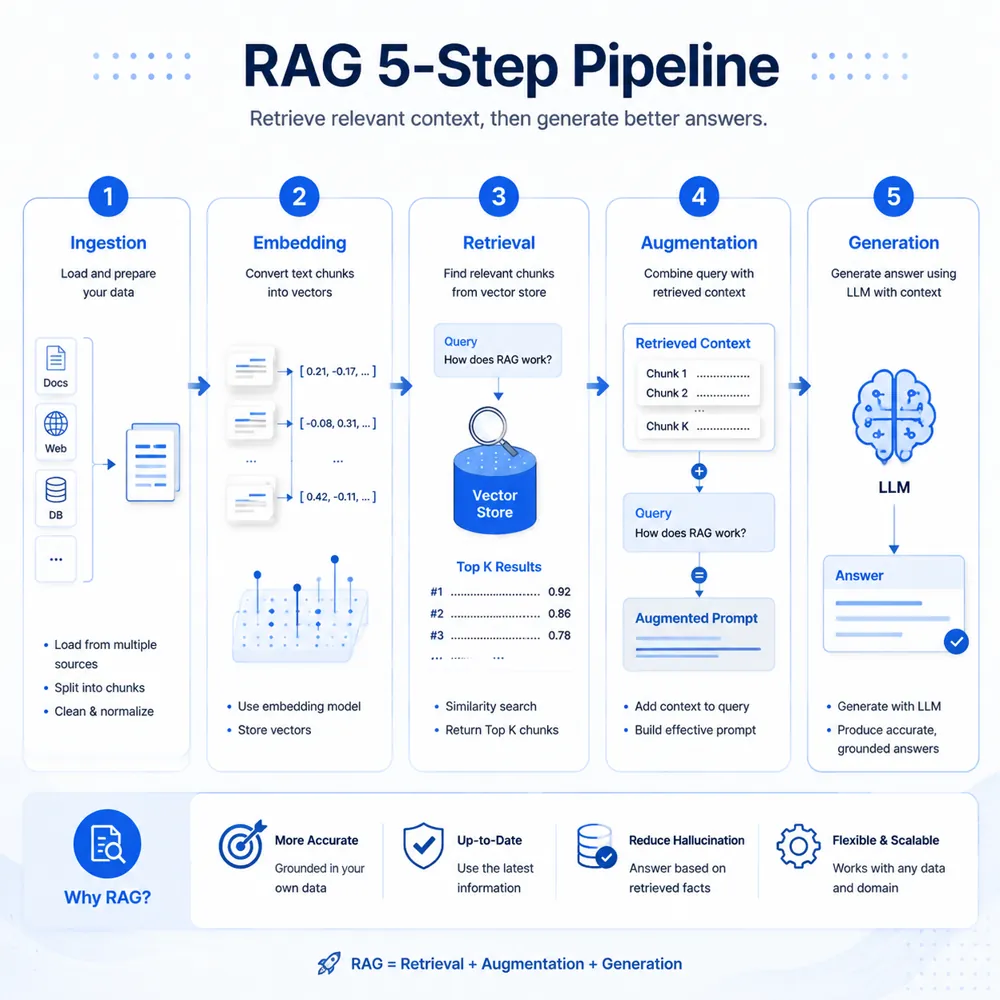
离线入库流程(一次性,耗时分钟到小时):
第一步,文档加载。支持PDF、Word、Excel、Markdown、网页、Notion、飞书文档、Confluence等几乎所有常见格式。LangChain和LlamaIndex提供了上百种Loader,覆盖各种数据源。
第二步,文档清洗。去除乱码、合并断行、保留表格结构、剔除页眉页脚。这一步看似简单,实际对最终效果影响巨大——脏数据会让Embedding质量严重下降。
第三步,文档切分(Chunking)。这是RAG工程里最关键的环节之一。原则是”按语义切,每段不要太长”。推荐配置:每段300-500字,相邻段重叠50字(避免关键信息被切断)。进阶玩法有父子分段(保留文档结构,检索子段但返回父段上下文)、QA分段(先用LLM把文档转成问答对再入库)。
第四步,Embedding向量化。用Embedding模型把每段文本转成高维向量(通常768-1024维)。“年假怎么算”和”带薪休假规定”在向量空间里会非常接近,因为它们的语义相似——这就是向量检索能”理解语义”的原因。
第五步,存入向量数据库。向量、原文、元数据(来源文档、页码、更新时间等)一并入库。
在线问答流程(每次提问,秒级响应):
第一步,用户提问”公司年假怎么算?”。
第二步,问题走同一个Embedding模型变成向量。
第三步,向量数据库做相似度检索(常用余弦相似度或欧氏距离),返回Top K(一般3-10)个最相关片段。
第四步,把Top K片段+用户问题拼成Prompt(带引用编号,如【1】【2】)。
第五步,大模型基于真实资料生成带引用的最终答案。
整个过程最关键的指标是检索召回率(Recall@K)——即正确答案出现在Top K结果里的比例。如果检索阶段没找到正确答案,再强大的大模型也救不回来。所以RAG项目里,切分策略+Embedding模型+检索算法三件套才是核心优化点,而不是大模型本身。
三、技术栈选型:4大组件+2026年推荐方案
搭建RAG需要4个核心组件,每个组件都有多种选择。选型没有标准答案,匹配业务场景和数据规模才是关键。
1. Embedding模型(文本→向量)—— 决定检索质量的上限
- 中文首选:BGE-large-zh-v1.5、BGE-M3(智源出品,Hugging Face开源免费,业界事实标准)
- 多语言:multilingual-e5-large(微软,100+语言支持)
- 商用API:OpenAI text-embedding-3-small、阿里云通义Embedding、智谱AI Embedding
- 选型建议:纯中文场景用BGE-M3,混合语言用mE5,预算充足直接用OpenAI API
2. 向量数据库(存储+相似度检索)—— 决定系统能跑多大
- 个人/小团队(<10万条):Chroma——Python库,零配置,5行代码跑起来
- 中型项目(10万-千万级):Qdrant / Weaviate——Rust/Go实现,高性能,支持丰富元数据过滤
- 企业级(亿级+):Milvus / Milvus Cloud——国产,中文社区活跃,分部署部署友好
- 全托管SaaS:Pinecone / 阿里云DashVector / 腾讯云VectorDB——免运维,按量付费
- 选型建议:先用Chroma跑通MVP,再根据数据量迁移。详细对比见向量数据库选型指南。
3. 大模型(生成答案)—— 决定答案质量和成本
- 云端API:GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro——效果最好,按量付费
- 国产云端:通义千问Max、DeepSeek-V3、文心一言4.0——中文场景性价比高
- 开源本地:Qwen2.5-72B、DeepSeek-V3、Llama 3.3-70B——用Ollama本地部署,数据完全离线
- 选型建议:中文场景首选Qwen2.5或DeepSeek-V3,效果+性价比+可控性三方面综合最优
4. 文档处理框架—— 决定开发效率
- Python库:LangChain(最流行,生态最全,组件丰富)/ LlamaIndex(专注RAG,API更简洁)
- 可视化平台:Dify / FastGPT / Coze(拖拽式,5分钟搭一套,业务人员也能用)
- 选型建议:学习用LangChain,生产用Dify,业务人员用Coze,深度定制用LangChain+LlamaIndex组合
四、5步搭建你的第一个RAG系统
不写代码也能做RAG。推荐用Dify可视化操作,新手5分钟上手,老手半小时上线完整业务系统。代码党可以参考RAG项目实战教程。
Step 1:部署Dify(一行命令)
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
# 访问 http://localhost/install 完成初始化需要8GB+内存,建议用云服务器或本地Docker Desktop。Windows用户需要先安装WSL2。详细部署步骤见Dify从0到1教程。
Step 2:配置Embedding模型
在Dify后台”设置→模型供应商”中添加Embedding:
- 本地Ollama:
bge-large-zh-v1.5(免费,需先部署Ollama,参考Ollama本地部署教程) - 云端API:OpenAI text-embedding-3-small(按量付费,约0.02美元/百万token)
- 国内云:阿里云DashScope Embedding(中文优化,新用户有免费额度)
Step 3:上传+切分文档
Dify支持拖拽上传PDF、Word、Excel、Markdown、网页链接。切分策略建议从”通用模式”开始(每段500字,重叠50字),再根据召回效果微调。
进阶策略:
- 父子分段:适合技术文档、产品手册,保留章节结构
- QA分段:先用LLM把文档转成”问题-答案”对再入库,特别适合FAQ类内容
- 按页切分:适合扫描版PDF、按页组织的内容
Step 4:建立知识库 + 召回测试
点击”创建知识库”→上传文件→自动Embedding入库,整个过程完全离线(如果用本地模型)。
关键步骤:入库后用10-20个真实问题做召回测试。在Dify的”召回测试”功能里输入问题,看Top 5里有没有正确答案。如果召回率低于80%,按以下顺序优化:
- 调整切分粒度(太粗/太细都不行)
- 换Embedding模型(BGE-M3通常比bge-large-zh效果更好)
- 开启混合检索(向量+关键词双路召回)
- 增加Query改写(让LLM把用户问题改写成多个相关问法)
Step 5:发布问答应用
关联知识库→选大模型(推荐Qwen2.5或GPT-4o)→调整Prompt模板→发布为:
- Web聊天界面(嵌入企业内网,给员工用)
- API接口(对接业务系统,如工单系统、CRM)
- 飞书/钉钉/企微机器人(员工直接@机器人提问)
- 微信小程序(对外客服场景)
五、3大商用方案对比与成本
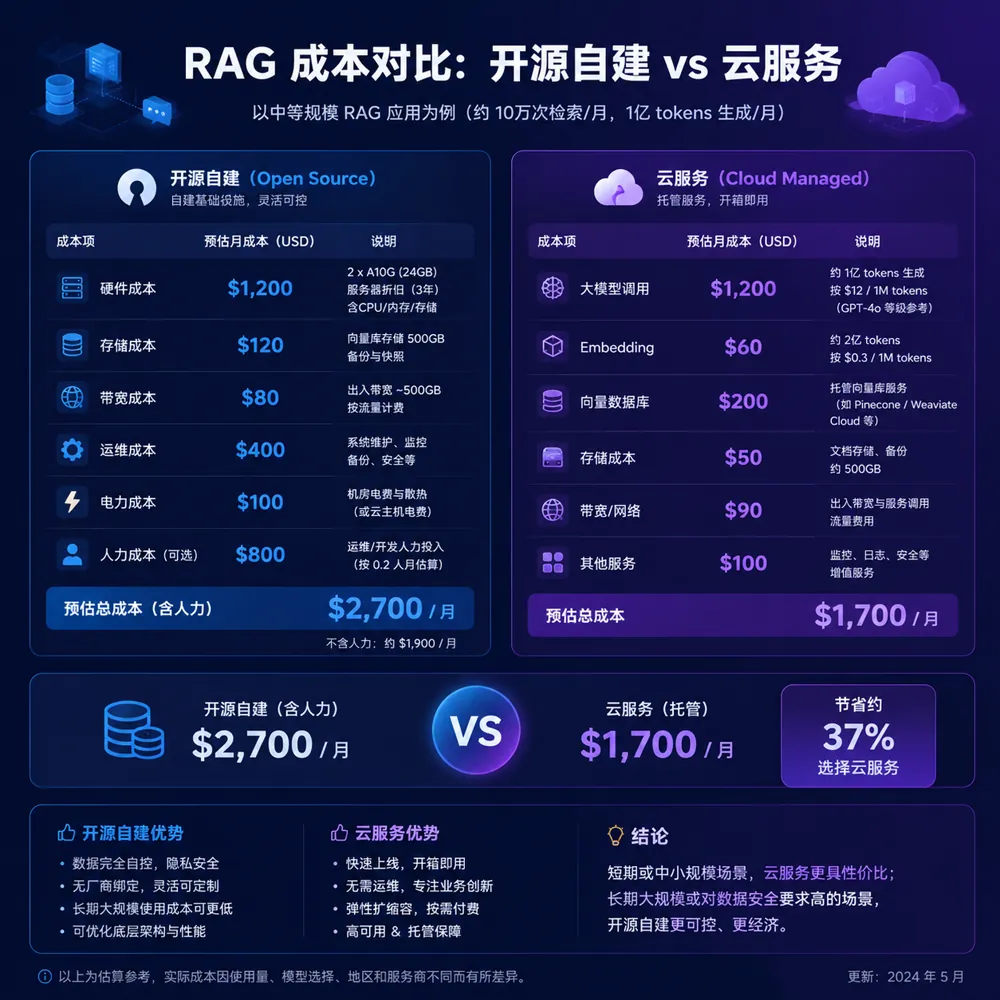
2026年RAG商用已经非常成熟,三种方案各有适用场景。选型的核心是回答两个问题:数据能否上云? 和 谁来维护?
方案A:Dify Community(开源自部署) ⭐ 数据敏感首选
- 成本:云服务器约200-500元/月(2核4G起步,10万文档以内)
- 优势:数据100%私有、可深度定制、Apache 2.0协议免费商用
- 适合:金融、医疗、法律、政府、制造等数据敏感行业
- 学习成本:低(可视化操作),深度定制需懂Docker和Python
- 生态:GitHub 90k+ stars,国产开源之光,中文社区非常活跃
方案B:Coze扣子(字节SaaS) ⭐ 业务人员首选
- 成本:免费版够用个人/小团队;专业版约99元/月;企业版按席位收费
- 优势:零运维、一键发布到飞书/抖音/微信公众号/网页、可变现(Bot商店)
- 适合:内容创作者、运营、客服、市场人员快速搭建AI应用
- 限制:数据在字节云上,数据敏感行业慎用
- 详细教程:Coze扣子从入门到变现
方案C:FastGPT(国产开源) ⭐ 企业级首选
- 成本:自部署免费;云服务约300-800元/月
- 优势:企业级Workflow编排、API完善、支持百万级文档、可视化Flow编排
- 适合:中大型企业知识中台、客服系统、智能问答平台、垂直行业SaaS
- 特色:国产项目,中文文档完善,支持国产化部署(信创)
快速选型决策树:
- 数据敏感行业 → Dify / FastGPT 自部署
- 快速验证MVP → Coze SaaS
- 业务系统集成 → Dify + API
- 非技术人员主导 → Coze 可视化
- 企业级Workflow → FastGPT
六、RAG常见问题与避坑指南
Q1:RAG答案还是不准怎么办?
排查顺序:①Embedding模型是否适合中文(BGE-M3通常最优)②切分粒度是否合适(太粗检索不准,太细丢失上下文)③Top K是否太小(建议3-10)④Prompt是否让模型”基于资料回答,不要编造”⑤是否需要Hybrid Search(向量+关键词混合检索)⑥是否需要ReRank精排(BGE-Reranker效果提升明显)。
Q2:文档很多(10万+)检索慢怎么办?
方案:①用Milvus/Qdrant等高性能向量库替代Chroma ②加元数据过滤(按部门/时间/类型缩小检索范围)③用HNSW索引(默认开启,毫秒级响应)④考虑Embedding缓存(相同文本不重复计算)⑤分布式部署向量库。
Q3:怎么评估RAG效果?
3个核心指标:①Context Recall(上下文召回率,正确答案是否被检索到)②Context Precision(上下文精确率,检索结果里有多少是相关的)③Faithfulness(答案忠实度,答案是否基于检索内容,没编造)。工具推荐RAGAS(开源评估框架,Python库,一行命令评估)。
Q4:RAG和Agent怎么结合?
高级玩法:让Agent在RAG检索之外,还能调用工具(搜索、计算、数据库查询、API调用)。用LangChain/LlamaIndex的Agent框架实现。例如:用户问”去年Q3销售额和增长趋势”,Agent先RAG查内部报告,再用计算器算增长率,最后总结输出。
Q5:RAG的安全风险?
主要风险:①Prompt注入(恶意文档可能让模型泄露其他文档内容)②越权访问(用户A检索到用户B专属文档)③数据泄露(日志/缓存未清理)。解决方案:①加Prompt模板限制 ②按用户/部门做权限过滤 ③日志脱敏 ④敏感字段加密存储。
七、写在最后:2026年RAG的红利与行动清单
RAG不是银弹,但它是大模型落地”私有知识”场景的最优解——成本低、效果可控、数据安全。2026年不会Fine-tuning不要紧,不会搭RAG真的会错过这波AI红利。看看身边,会用RAG的客服已经一个人顶10个人,会用RAG的律师已经一周搞定一个月的工作量。
立刻行动清单:
- ✅ 本地用Dify搭一套(1小时,跟着Dify教程走)
- ✅ 喂入你最常用的10篇文档(产品手册/FAQ/SOP)
- ✅ 体验”问就有答、答有出处”的感觉
- ✅ 用RAGAS评估效果,迭代优化到召回率>85%
- ✅ 接入业务系统(客服工单/HR问答/销售助手)
- ✅ 沉淀为团队标准工具,赋能更多同事
RAG的门槛比想象中低得多。推荐先从Dify可视化开始,跑通流程后再考虑深度定制。等到业务跑通、数据量上来,再评估是否需要迁移到Milvus、是否需要Fine-tuning、是否需要混合架构。
AI不会取代人,但会用RAG的人一定会取代不会用的人。从今天开始,搭建你的第一个企业知识库吧。